

MLflow es una plataforma open-source para gestionar el ciclo de vida del desarrollo Machine Learning de principio a fin, y para esto incluye 4 funcionalidades/módulos principales:
- Tracking de experimentos para registrar y comparar parámetros y resultados (MLflow Tracking).
- Empaquetado el código ML de forma reutilizable y reproducible para compartirlo con otros científicos de datos y desplegarlo en producción (MLflow Projects).
- Gestión y despliegue de modelos desde una gran variedad de bibliotecas de ML a una variedad de plataformas para su serviciado (MLflow Models)
- Proporcionar un almacén central de modelos para gestionar de forma colaborativa el ciclo de vida completo de un modelo MLflow, incluyendo el versionado de modelos, las transiciones de etapas y las anotaciones (MLflow Model Registry).
MLflow es agnóstico a las diversas librerías, se puede usar con cualquier biblioteca de aprendizaje automático, y en cualquier lenguaje de programación, ya que todas las funciones son accesibles a través de su REST API y CLI además de incluir Python API, R API y Java API.
Antes de entrar en sus módulos (Tracking, Projects, Models, Model Registry) veamos un ejemplo que muestra todos los pasos de un desarrollo ML, desde el desarrollo a
Instalación
1.Instalamos Python3 (en mi caso instalaré Python3.8
sudo apt update sudo apt install python3.8 alias python=python3.8
2.Instalamos pip3
sudo apt update sudo apt install python3-pip

3.Instalo MLFlow y scikit-learn que lo usaremos en el ejemplo
sudo pip3 install mlflow pip install scikit-learn pip install pandas

4.Instalo Conda, en mi caso he elegido Miniconda, para eso en función de mi versión de Python seleccionaré uno de los instaladores de https://docs.conda.io/en/latest/miniconda.html#linux-installers
Una vez descargado el sh lo ejecutaré con
sudo bash Miniconda3-latest-Linux-x86_64.sh

Ejemplo
Me clonaré el repositorio de github de mlflow y me iré al directorio examples para acceder a sus ejemplos:
git clone https://github.com/mlflow/mlflow
Dentro de examples tenemos la carpeta sklearn_elasticnet_wine que es una regresión lineal para predecir la calidad del vino basado en características del vino como “fixed acidity”, “pH”, “residual sugar” que vienen en el dataset wine-quality.csv
wine-quality.csv (https://github.com/mlflow/mlflow/blob/master/examples/sklearn_elasticnet_wine/wine-quality.csv)

El código está en el fichero train.py (https://github.com/mlflow/mlflow/blob/master/examples/sklearn_elasticnet_wine/train.py)
El ejemplo utiliza las APIs de pandas, numpy y sklearn para crear un modelo simplede aprendizaje automático.
Las APIs de Tracking de MLflow registran información sobre cada ejecución de entrenamiento, como los hiperparámetros alpha y l1_ratio, utilizados para entrenar el modelo y las métricas, como el error cuadrático medio, utilizadas para evaluar el modelo.
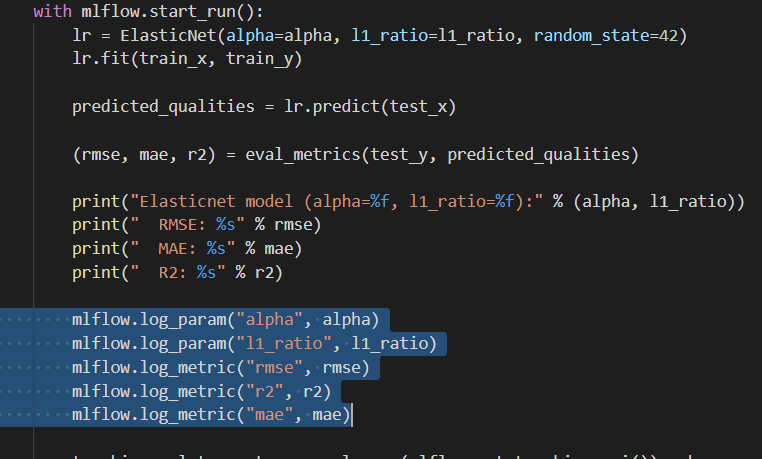
El ejemplo también serializa el modelo en un formato que MLflow sabe desplegar.

Podemos ejecutar el ejemplo con los hiperparámetros por defecto así:
python sklearn_elasticnet_wine/train.py
O bien con otros parámetros
python sklearn_elasticnet_wine/train.py <alpha> <l1_ratio>

Una vez he realizado varias ejecuciones puedo comparar los modelos, para eso ejecuto desde el mismo directorio:
mlflow ui
y abro http://localhost:5000

Podemos ver la ejecución con las métricas obtenidas para cada una de ellas.
Seleccionando uno de los modelos puedo ver los detalles:

Incluyendo el artefacto generado:
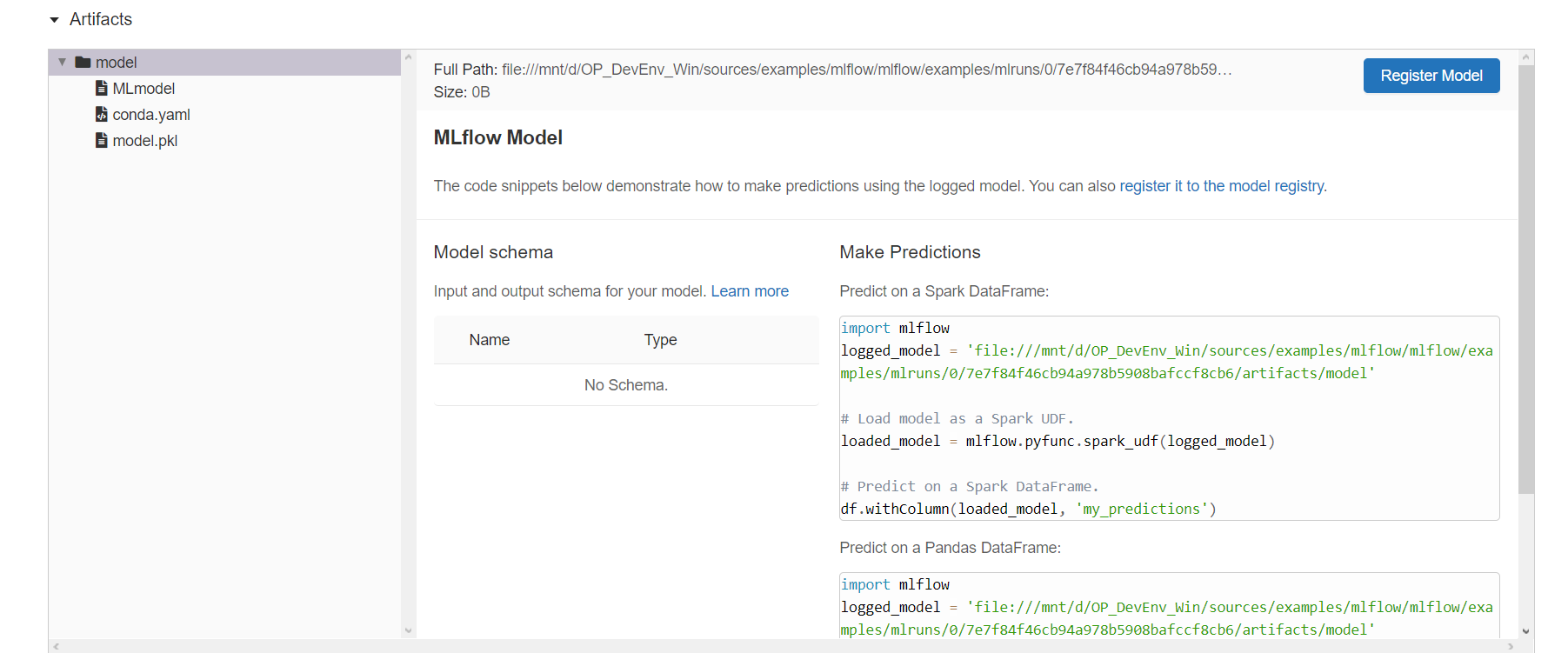
En un siguiente post empaquetaremos el código en un Entorno Conda y lo serviremos a través de un endpoint REST.

Deja un comentario