
Apache Pinot (https://pinot.apache.org) es un almacén de datos OLAP open-source distribuido en tiempo real, construido para ofrecer análisis escalables en tiempo real con baja latencia. Puede ingerir datos de fuentes por lotes (como Hadoop HDFS, Amazon S3, Azure ADLS, Google Cloud Storage), así como fuentes de datos de flujo (como Apache Kafka)
Este motor OLAP ofrece capacidades analíticas todo-en-uno, el motor motor permite consultar los datos en bruto sin apenas transformación con gran rendimiento ofreciendo una visión unificada de los datos, la ingestión de datos en tiempo real y en Batch desde diversas fuentes, la indexación distribuida, soporte SQL, interfaz JDBC y ODBC, soporte de datos en caliente y en frío, múltiples integraciones y un almacén de metadatos.
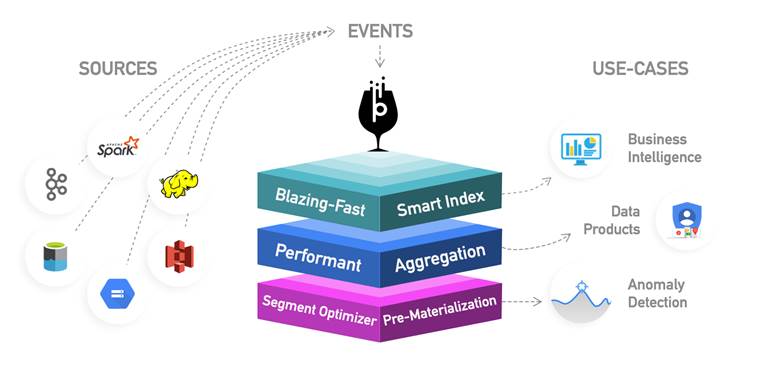
Pinot fue diseñado para escalar el rendimiento de las consultas en función del número de nodos de un clúster. A medida que se añaden más nodos, el rendimiento de las consultas siempre mejorará en función de la cuota de volumen de consultas por segundo (QPS) prevista. Sus principales características son:
- Alta disponibilidad: Pinot está construido para servir consultas analíticas de baja latencia para aplicaciones orientadas al cliente. El sistema sigue sirviendo consultas cuando un nodo se cae.
- Escalable horizontalmente: Capacidad de escalar añadiendo nuevos nodos a medida que cambia una carga de trabajo.
- Latencia frente a almacenamiento: Pinot está diseñado para ofrecer una baja latencia incluso con un alto rendimiento. Para ello, se han desarrollado características como la estrategia de asignación de segmentos, la estrategia de enrutamiento o la indexación en estrella.
- Datos inmutables: Pinot asume que todos los datos almacenados son inmutables. Para el cumplimiento de la normativa GDPR, ofrecemos una solución complementaria para la purga de datos, manteniendo las garantías de rendimiento.
- Cambios de configuración dinámicos: Las operaciones como la adición de nuevas tablas, la ampliación de un clúster, la ingesta de datos, la modificación de la configuración de indexación y el reequilibrio pueden realizarse sin afectar a la disponibilidad o el rendimiento de las consultas.
En la figura podemos ver como Pinot soporta la ingesta tanto en Batch (Ingestión Job) como en Streaming (Realtime ingest)
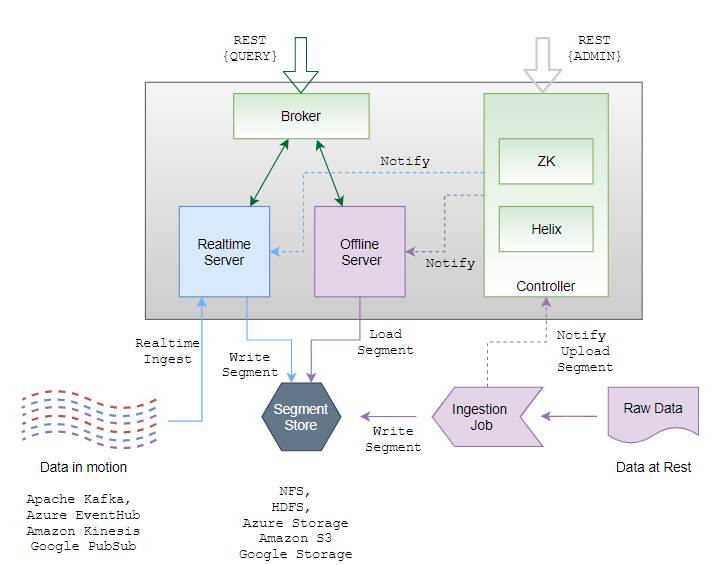
Además, Pinot no incluye una capa de almacenamiento si no que se puede configurar para almacenar sobre alguno de estos file systems (S3, HDFS, Azure Data Lake Storage, Google Cloud Storage) , lo que nos permitirá integrar Pinot con los datos almacenados en S3 y en HDFS, de modo que podré acceder a estos datos en un escenario OLAP:


Deja un comentario