

¿Qué es?
PrestoDB es un motor de consultas SQL distribuido open-source y contruido en Java, está pensado para lanzar consultas analíticas interactivas contra un gran número de fuentes de datos (a través de conectores) soportando consultas sobre fuentes de datos que van desde gigabytes hasta petabytes.
Presto es un motor de consulta ANSI-SQL, permite consultar y manipular datos en cualquier fuente de datos conectada con las mismas sentencias, funciones y operadores SQL.
PrestoDB vs Trino
PrestoDB fuese creado en 2012 en Facebook donde inicialmente se creó para para resolver el problema de la lentitud de HIVE al acceder a un data-warehouse de 300 PB. Para resolver este problema se construyó un motor MPP basado en SQL que fuera fácil de usar a partir de los conocimientos existentes, fácil de conectar a cualquier base de datos, almacén o datalake y fácil de integrar con cualquier herramienta de BI.
Por otro lado tenemos Trino (o PrestoSQL)

En 2018 una par de los creadores de PrestoDB dejaron Facebook para crear una comunidad open-source de PrestoDB bajo el nuevo nombre de PrestoSQL. Mientras que PrestoDB se construyó para que las consultas fueran más eficientes en volúmenes muy grandes, PrestoSQL se construyó para una variedad mucho más amplia de clientes y casos de uso. En diciembre de 2020, PrestoSQL pasó a llamarse Trino. Empresas como LinkedIn, Lyft, Netflix, GrubHub, Slack utilizan Trino en la actualidad.
¿Qué podemos hacer?
Presto permite consultar los datos sobre su origen, incluyendo entre otros conectores Hive, Cassandra, bases de datos relacionales Kafka, Kudu, Redis, MongoDB. Una sola consulta de Presto puede combinar datos de múltiples fuentes, lo que permite realizar análisis multi-store.
Presto está enfocado a consultas analíticas que esperan tiempos de respuesta que van desde menos de un segundo hasta minutos.
Ofrece una línea de comandos para hacer las consultas:

Conectores
Presto ofrece os conectores disponibles en Presto para acceder a los datos de diferentes fuentes de datos, podéis ver el listado aquí: https://prestodb.io/docs/current/connector.html
Entre ellos conector Accumulo, Cassandra, Druid, Elasticsearch, HIVE, JMX, Kafka, Kudu, ficheros locales, MongoDB, MySQL, Oracle, Postgresql, Redis, Redshift, SQL Server,…

Driver JDBC
Presto ofrece un driver JDBC que permite acceder a las fuentes de datos subyacentes desde cualquier aplicación que use el driver, por ejemplo para conectar con HIVE sería:

El driver es un JAR:
Presto Web UI
Presto proporciona una interfaz web para supervisar y gestionar las consultas. La interfaz web es accesible en el coordinador de Presto a través de HTTP.
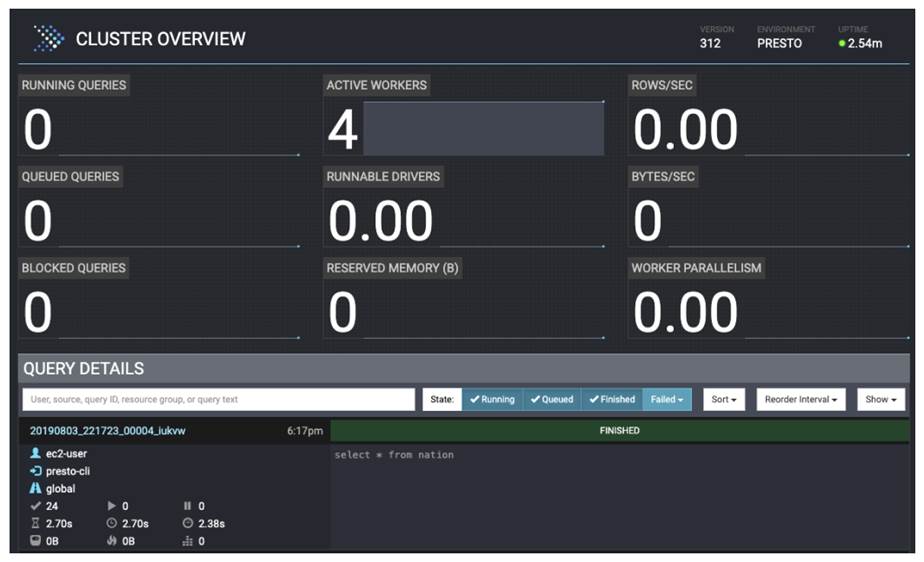
El UI nos indicara para cada query su estado:

Ejecutar Presto sobre Spark
Presto on Spark permite aprovechar Spark como entorno de ejecución para las consultas de Presto. Esto es útil para las consultas que queremos ejecutar en miles de nodos, que requieren 10 o 100 terabytes de memoria y que consumen muchos años de CPU. Spark proporciona varios valores añadidos como el aislamiento de recursos, la gestión de recursos de grano fino y el mecanismo de intercambio materializado escalable de Spark.
Control de Acceso
Presto ofrece un plugin de control de acceso al sistema que impone la autorización a nivel global, antes de cualquier autorización a nivel de conector.
Puede utilizarse uno de los plugins incorporados en Presto o crear el propio siguiendo las directrices de Control de acceso al sistema.
Presto ofrece tres plugins incorporados:

Algunas extensiones interesantes
Alrededor de PrestoDB hay un ecosistema que permite ampliar el uso de PrestoDB, entre estas:
- Proyecto Aria permite hacer Push-down de expresiones completas a la fuente de datos par algunos formatos como ORC
- Presto Unlimited – introduce la materialización para crear tablas temporales en memoria para utilizar mucha menos memoria.
- Funciones definidas por el usuario – permite crear funciones SQL dinámicas
- Conectores Apache Pinot y Druid
- RaptorX – Desagrega el almacenamiento del procesamiento para lograr baja latencia y proporcionar una solución unificada para casos de uso OLAP e interactivos.
- Presto-on-Spark – Ejecuta el código de Presto como una biblioteca dentro del ejecutor de Spark.

Deja un comentario