

Nebula Graph es una base de datos de gráficos de código abierto capaz de albergar grandes grafos (según indican con miles de millones de vértices (nodos) y trillones de bordes (edges) con una latencia de milisegundos.
Nebula Graph está pensada para ofrecer un alto rendimiento y simplificar el uso de grafos.
Comparando con otras bases de datos de grafos, Nebula ofrece:
- Distribuida simétricamente
- Separación de almacenamiento y computación
- Escalabilidad horizontal
- Fuerte consistencia de datos por el protocolo RAFT
- Lenguaje de consulta tipo SQL
- Control de acceso basado en roles
Arquitectura
La Arquitectura de Nebula Graph se puede representar así:

Cómo se usa
Veamos cómo se usa Nebula Graph siguiendo su Getting Started:
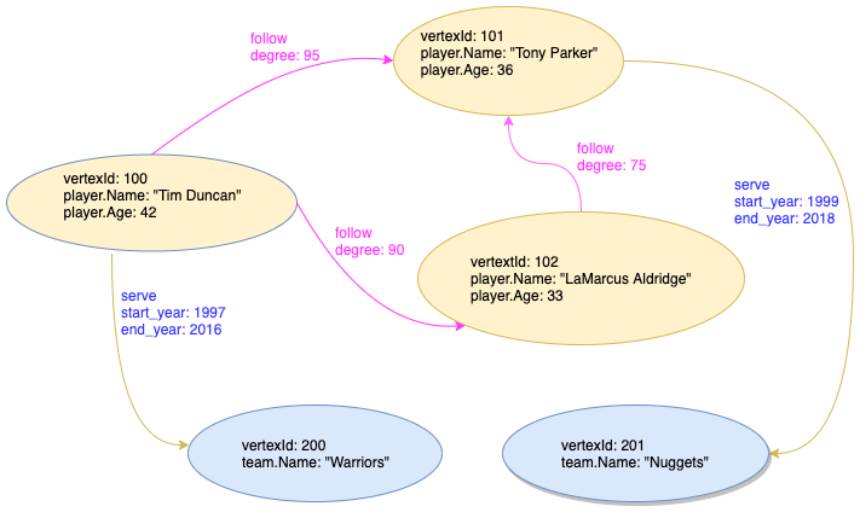
Partiendo de este ejemplo:
Creando un graph space
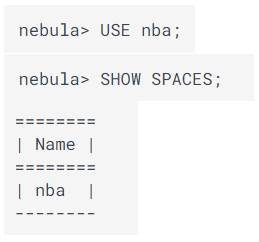
Lo primero es crear un graph space, que sería el equivalente a crear una base de datos en una BD relacional:
Desde la consola de Nebula puedo ejecutar:
![]()
Donde partition_num representa el número de particiones en una réplica y replica_factor el número de réplicas en el cluster (típicamente 3 en producción):
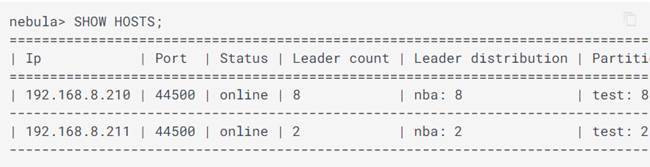
Una vez ejecutado podría comprobar el estado del cluster:
Tras crear el graph space seleccionaré su uso
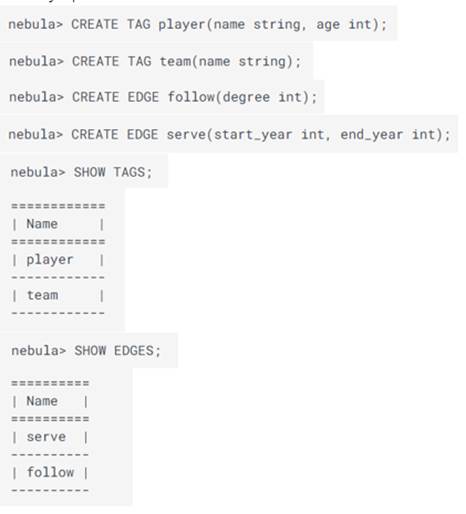
Definiendo un esquema
En Nebula se clasifican los vértices con propiedades similares en un grupo que se llama tag que se crea con el comando CREATE TAG mientras que un Edge se crea con un CREATE EDGE.
Para el ejemplo tenemos:
CRUD de datos
Siguiendo con el ejemplo veamos ahora como insertar un VERTEX indicando su tag, su vertex ID y sus propiedades:

Y tras esto los edges indicando el tipo de EDGE, vertex ID del fuente y vertex ID del destino con sus propiedades:

Y tras insertar los datos puedo consultar, para eso puedo usar el FETCH indicando el vertex tag y vertex ID:
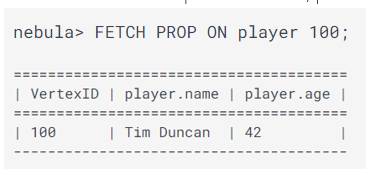
También puedo recuperar los datos del Edge serve entre VID 100 y 200:
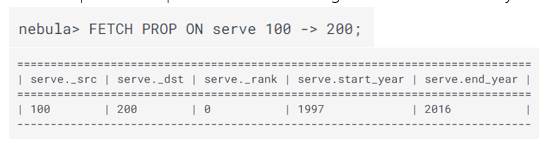
Puedo además de esto usar el UPDATE, UPSERT, DELETE,…

También puedo crear índices:
![]()
Veamos alguna query adicional:

Nebula Graph Studio:
Nebula incluye una herramienta UI web que permite explorar los grafos de forma visual, Nebula Graph Studio:
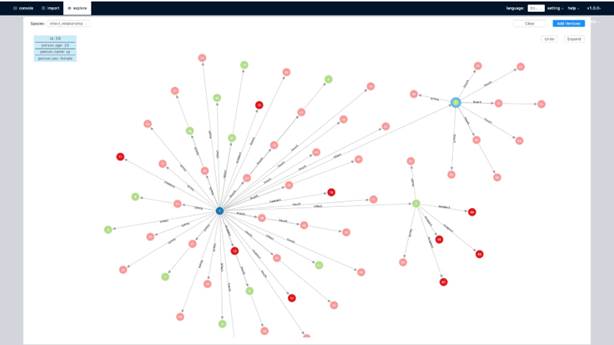
Permite ejecutar las consultas en lenguaje nSQL:
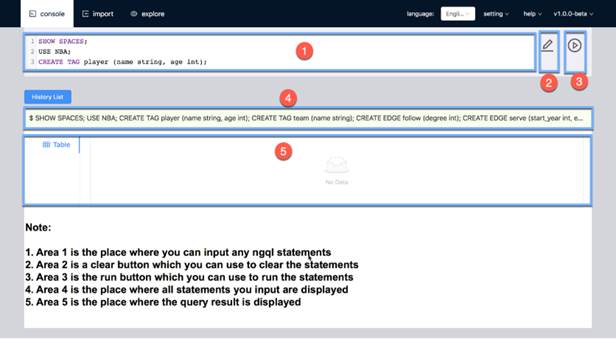
O importar ficheros CSV en la base de datos:

Ver guía de usuario de Nebula Graph Studio.
Comparando el Rendimiento de Nebula Graph
Como dijimos al principio Nebula Graph está creada con foco en obtener un gran rendimiento, en este artículo comparan en cuanto a rendimiento Neo4J, JanusGraph y Nebula Graph
Ya sabemos que este tipo de base de datos son especialmente exigentes en el consumo de memoria, así que el HW de pruebas
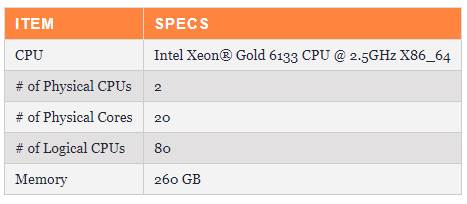
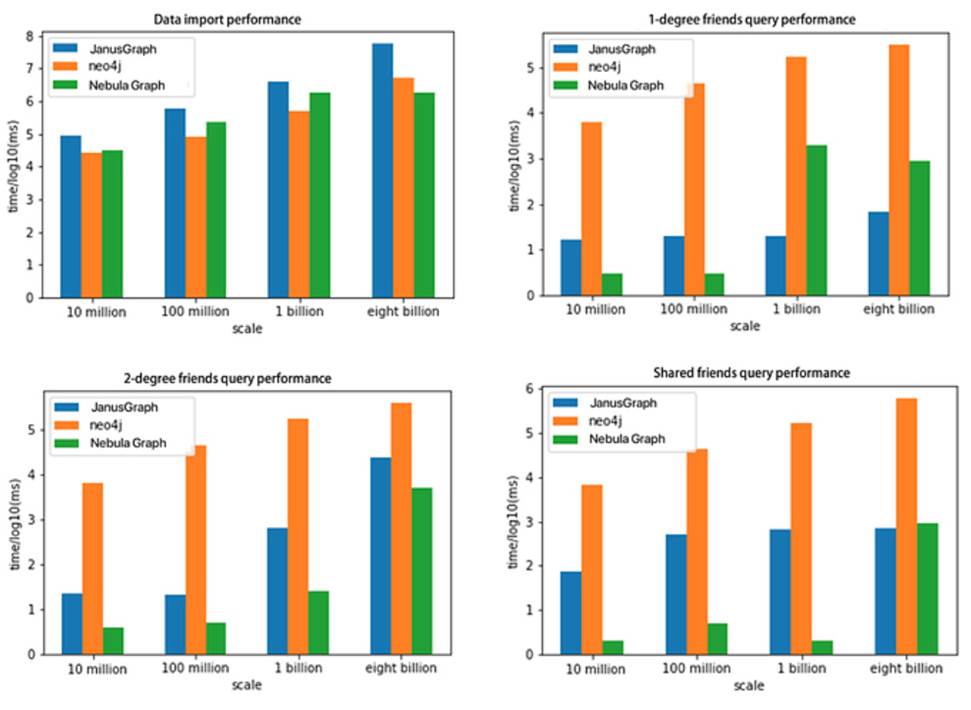
El resumen de los datos de la prueba puede verse en este gráfico:
Comparando sintaxis de consultas
Aunque el artículo anterior se centraba en el rendimiento tanto o más interesante me resulta la diferencia en la sintaxis entre las 3 bases de datos:


Deja un comentario