
Fue allá por 2016 cuando conocía Druid (ver post)
En este whitepaper podéis encontrar información mucho más detallada sobre la propuesta de Apache Druid:

En el whitepaper se hablan sobre
Casos de uso típicos de Druid

Cuándo usar Druid:
- Insert rates are very high, but updates are less common.
- Most of your queries are aggregation and reporting queries ("group by" queries). You may also have searching and scanning queries.
- You are targeting query latencies of 100ms to a few seconds, such as to power a user-facing application where you want your users to be able to self service iterative ad hoc queries (i.e. data exploration), perhaps through a visual interface.
- You have a large number of concurrent users, such as operational staff across your company, or end customers.
- You have very large data volumes, from many terabytes to petabytes.
- Your data has a time component. Druid includes optimizations and design choices specifically related to time.
- You have high cardinality data columns (e.g. URLs, user IDs) and need fast counting and ranking over them.
- You want to load streaming data from sources like Apache Kafka (Druid supports exactly once semantics) or Amazon Kinesis, or batch data from HDFS, flat files, or an object storage like Amazon S3, Google Cloud Storage or Azure Storage
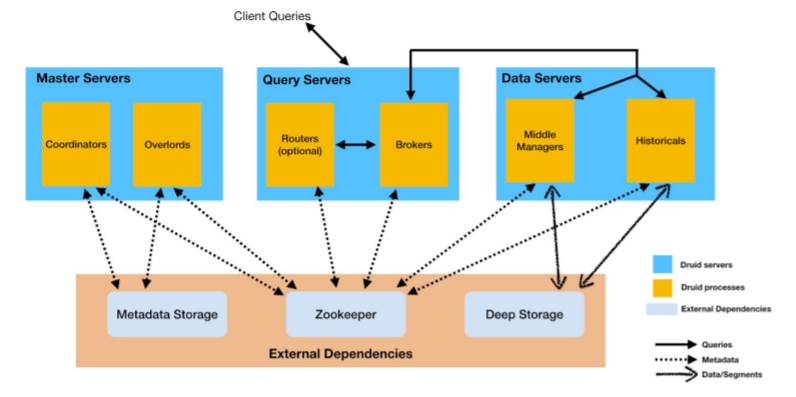
Arquitectura Druid:

Deja un comentario