

Seguimos en este post profundizando en la interesante base de datos Azure Cosmos DB (ver post previo)
Como ya decíamos Cosmos DB es una base de datos muy interesante, ya que ofrece un gran número de funcionalidades que habilitan que encaje en un amplio número de casos de uso.
PRINCIPALES CARACTERÍSTICAS DE COSMOS DB
Las principales características de Cosmos DB son estas:
- BD Multimodelo: Cosmos DB es una base de datos que soporta almacenamiento Clave-Valor, documental, columnar y de grafos.
- BD distribuida globalmente: Cosmos DB puede desplegarse entre regiones soportando despliegues multimaestro
- BD escalable: la capacidad de lectura y escritura se gestiona a través de las RUs (Read Units) que permite escalar conforme nos interesa.
- Baja latencia: conforme Azure Cosmos DB es capaz de garantizar lecturas bajo 10ms en el percentil 99% (en la misma región Azure)
- Alta disponibilidad: los datos pueden replicarse entre regiones. En un despliegue en una región se consiguen SLAs de 99,99% y en un despliegue multi-región el SLA es de 99,999%. (los datos se distribuyen entre particiones, y en cada región se replican las particiones)
- API Cassandra y API MongoDB: lo que nos permite migrar desde estas bases de datos con unos cambios mínimos
- API SQL: es la versión nativa de CosmosDB, en función del tipo de modelo puede devolver los datos como un JSON (documental al estilo Mongo)
- API Gremlin: para manejar BD de grafos (API basada en Apache TinkerPop)
NIVELES DE CONSISTENCIA
Cosmos DB permite configurar la consistencia para primar 2 de los 3 criterios del teorema CAP: Consistencia, Disponibilidad y Tolerancia a Particiones (qué tiempos…allá por 2013, ver post)

De modo que podemos configurar Cosmos DB:
- Strong Consistency: el usuario nunca verá escrituras parciales o sin commit. Las lecturas garantizan que se devuelva la versión más reciente de un elemento. Con esto conseguimos la más alta consistencia y bajo throughput, además conforme escalemos la latencia al escribir crece.
- Bounded Staleness: en lugar de una consistencia del 100% este nivel permite un lag en las operaciones (como el dirty read). Permite configurar este lag.
- Session Consistency: es el nivel por defecto. La consistencia es alta a nivel de la sesión. Ofrece buenos rendimientos y throughputs.
- Consistent Prefix: las lecturas son consistentes en un momento pero no tiene porqué ser el actual (del orden de segundos). Buen rendimiento y alta disponibilidad.
- Eventual Consistency: no garantiza el tiempo que tomará que sea consistentes. Los updates pueden no hacerse en orden. Es la opción de mayor performance, más bajo coste (menos RUS) y alta disponibilidad.
INDEXADO
Por defecto Cosmos DB indexa cada propiedad de cada elemento (WTF?) aunque puede personalizarse especificando los índices a la hora de crear la tabla.
No olvidemos que los índices mejoran el performance de lectura pero afectan al rendimiento de escritura, además implican más datos (y por tanto más RUS y coste).
Cosmos DB soporte índices:
- Hash: para consultas =
- Range: para consultas por rangos y order
- Spatial: para queries espaciales (sobre Punto, Polígono y Líneas).
CLAVES DE PARTICIONADO
Cosmos DB ejecuta sobre contenedores, cada contenedor se divide en particiones lógicas basadas en la clave de partición. Un algoritmo Hash divide y distribuye los datos entre múltiples contenedores.

La asignación de las particiones lógicas sobre las particiones físicas se gestiona por CosmosDB para garantizar la alta disponibilidad. Cuando crecen los RUs se incrementan el número de particiones físicas.
Es importante elegir una clave de partición que permita separar los datos entre particiones lógicas.
THROUGHPUT:
El coste de CosmosDB depende mucho del throughput que configures y provisiones (CosmosDB crea particiones lógicas que se despliegan entre contenedores).
El throughput se expresa básicamente como RUS (Read Units) que definen las capacidades de lectura y escritura por contenedores o base de datos). Las RUS aíslan de los recursos del sistema como CPU, memoria, IOPS,…

ACCESO CON SDKS
Cosmos DB ofrece SDKS para varios lenguajes, entre ellos .Net, Java, Node.js, Python, Xamarin además de APIS Cassandra, MongoDB, Gremlin, Table,…
Ver más: https://docs.microsoft.com/es-es/azure/cosmos-db/
Cosmos DB ofrece un Data Explorer para poder acceder a mis elementos, haciendo queries en SQL, inserciones en JSON

Veamos cómo se usa el API Java SQL:
- Inicializo el CosmoClient indicando la MasterKey, el nivel de consistencia, política de conexión:

- Creo la Base de Datos:
![]()
- Creo el contenedor con 400 RUs:

- Inserto un elemento (JSON):
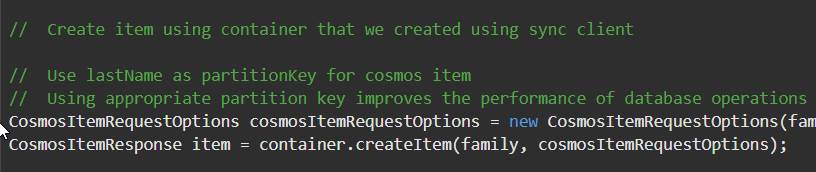
- Hago una consulta en SQL:

RECOMENDACIONES
- El performance, RUS consumidas,…puede monitorizarse desde la Página de Métricas. Puedes además crear aletas.

- Si los datos son muy críticos debes usar Replicación entre al menos 2 regiones
- CosmosDB permite automatizar los backups, indicando el periodo de retención, frecuencia,…
- CosmosDB soporta almacenamiento encriptado

Deja un comentario