
Tesseract OCR es un motor OCR open-source (libtesseract).
Inicialmente fue desarrollado en HP, que lo hizo open-source en 2005, desde el 2006 es desarrollado por Google bajo licencia Apache.
Tesseract ofrece Soporte unicode (UTF-8) support y puede reconocer más de 100 lenguajes "out of the box". Además puede entrenarse para reconocer más lenguajes (Tesseract Training)
El resultado pude ser un fichero plano, HTML, PDF,…
Tesseract está desarrollado en C++ pero ofrece wrappers en diversos lenguajes como Java, Android.:
Tesseract ofrece una línea de comandos, además existen otras aplicaciones con GUI (3rdParty) como el VietOCR en Java:
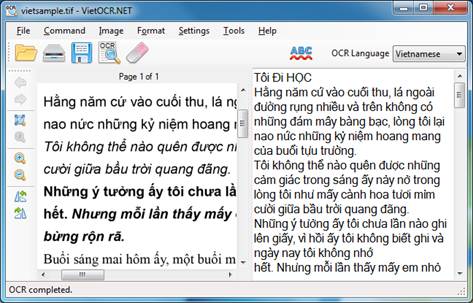
Podemos compilar Tesseract o usar una versión compilada para nuestro SO: https://github.com/tesseract-ocr/tesseract/wiki/Downloads
La última versión es de febrero de 2016.

Deja un comentario