
Ya nos hacíamos eco de Kudu en este post:
¿Qué es Kudu?
Aunque sigue en beta Kudu es una opción cada vez más a tener en cuanto como motor de almacenamiento que soporta actualizaciones y analítica sobre el mismo motor.
Como decíamos, el objetivo de Kudu es soportar actualizaciones e inserciones y scans sobre su repositorio columnar, por lo que Kudu complementar HDFS y HBase y simplifica la arquitectura de aplicaciones mixtas.
En GitHub tenemos un proyecto con ejemplos de uso de Kudu en Java, C++ y Python, como este, aunque sin duda lo más interesante es poder usarlo desde Impala como podemos ver aquí:
Podemos crear TABLAS:

O desde una SELECT:
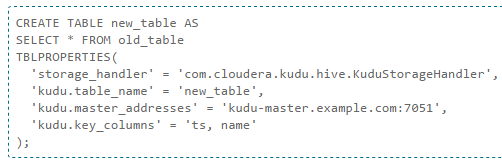
Particionarlas por RANGO:

O por HASH, o por ambos conceptos.
Hacer INSERTS:

UPDATES:
![]()
Y DELETES (incluso con operadores y JOINS)

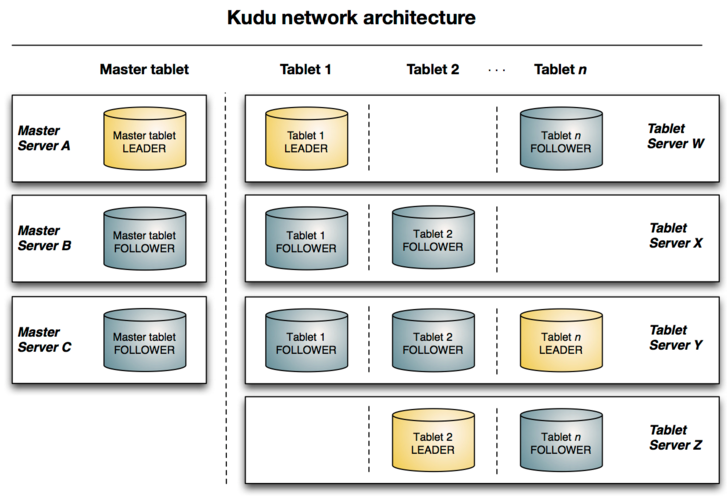
La Arquitectura de Kudu se basa en el concepto de TABLET:

Deja un comentario