
(Dedicado a Sebas y Julián)

Trabajar con datos en tiempo real es un funcionalidad cada más típica en Hadoop.
Hasta ahora podíamos usar Impala para analítica interactiva y Spark para procesamiento batch y en streaming.
A pesar de estos avances en la capa de almacenamiento normalmente teníamos que elegir:
· Analítica online sin capacidad de manejar modificaciones en tiempo real ( HDFS con Apache Parquet)
· Acceso aleatorio en tiempo real con coste en el rendimiento en el escaneado (Apache HBase).
De esta forma para aplicaciones analíticas en tiempo real que requieren rendimiento en la parte analítica y actualización online de datos se necesitan Arquitecturas Híbridas (como Sofia2)
Y aquí aparece Kudu, ya que ofrece una solución a esta complejidad y variedad.
Kudu es un nuevo motor de almacenamiento nativo en Hadoop diseñado para un alto rendimiento en Analítica online sobre datos actualizándose. Kudu tiene licencia Apache y está desarrollado por Cloudera.
Me ha resultado especialmente interesante esta comparativa:
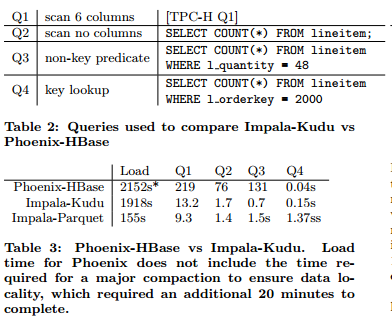
Actualmente Kudu está en beta, podéis leer más en este Technical Paper: Kudu: Storage for Fast Analytics on Fast Data
Podríamos decir que Kudu es como HDFS y HBase en uno

Deja un comentario