
Aprovechando la reunión de esta semana con el equipo de Pivotal (gracias Fred, Luis, Antonio) arranco hoy un conjunto de post (que tenía pendientes desde hace meses) sobre Spring XD.
Y para empezar el inicial ¿Qué es Spring XD?
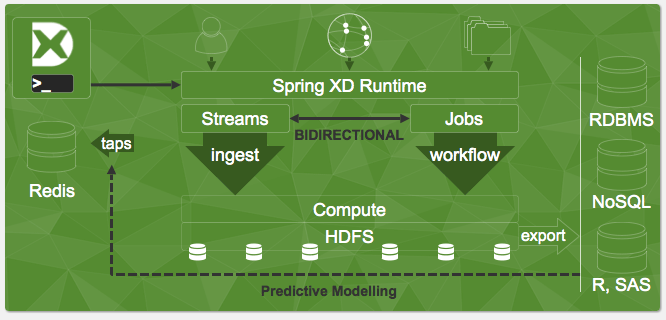
Spring XD (Spring eXtrem Data) es una Plataforma unificada, distribuida y extensible para la ingesta de datos, analítica en tiempo real, procesamiento batch y exportación de datos.
El objetivo del proyecto es simplificar el desarrollo de aplicaciones Big Data, y es el core del enfoque Big Data de Pivotal.
Spring XD está construido sobre Spring Boot como core de ejecución.
Spring XD se compone de 2 componentes clave:
· Admin Server
· Container Server
A través de una DSL (que puede construirse vía texto o desde consola web) se envía la descripción de las tareas a procesar (por ejemplo lectura de un fichero de log, filtrado de líneas y carga en base de datos) hacia el Admin Server que mapea las tareas a procesar en los módulos de proceso disponibles (Units of Execution), que están implementadas como Contextos de Spring (Spring Boot).
Spring XD tiene 2 modos de operación: Single y Multi-Node.
En el modo Single el Admin Server y 1 Container Server corren en el mismo proceso. Este modo es muy útil en desarrollo y en Prototipado.
El modo Distribuido se denomina DIRT (Distributed Integration RunTime) y distribuye los nodos de proceso (Units of Execution) en múltiples nodos, que pueden ser servidores físicos, VMs, AWS EC2, hosts Docker,…
A través de Flo podemos crear Streams (captura de datos en Streaming) y trabajos Batch de forma visual:

En un próximo post entraremos en los conceptos de Spring XD: sources, sinks, processors,…
sss

Replica a Luis Miguel Gracia Cancelar la respuesta