
HP Vertica (https://my.vertica.com/) es un plataforma analítica Big Data diseñada para ser rápida, simple y escalable.
Se trata de una base de datos distribuida, que se fundamenta en las siguientes características:
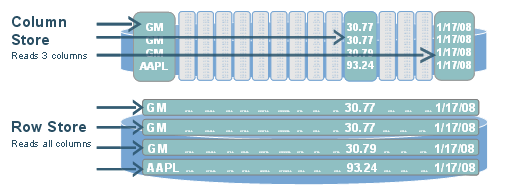
· Almacenamiento Columnar: Optimiza el acceso a los datos. La información se almacena en la forma en la que se consulta. El almacenamiento columnar es ideal para operaciones intensivas de lectura ya que reduce drásticamente el número de accesos a disco, en comparación con el almacenamiento basado en filas de las bases de datos relacionales.
· Compresion+Encoding: Permite almacenar más datos en menos espacio.
· Clustering: Facilidad de escalado
· Optimizacion continua automatica
Pese a ser columnar, Vertica se basa en estándares relacionales, por lo que soporta consultas SQL a través de drivers JDBC/ODBC, facilitando la integración con aplicaciones ya existentes que utilicen estos estándares.
Vertica es una plataforma de procesamiento distribuido masivo, que distribuye la carga de trabajo entre múltiples nodos de tipo commodity. Está optimizado para trabajar con grandes volúmenes de información balanceando entre memoria y disco. Asimismo, existen extensiones para analizar de series de tiempo, realizar analitica geoespacial y de sentimiento, así como ejecutar programas en R para realizar modelos predictivos.
Vertica es capaz de gestionar terabytes de información ejecutándose en equipos de coste relativamente bajo, resolviendo consultas entre 50 y 200 veces más rápido que las bases de datos orientadas a fila, así como de otros sistemas analíticos clásicos.
Este rendimiento se logra gracias a características como el almacenamiento columnar de la información, compresión de los datos, así como del almacenamiento redundante de la información, que permite tanto distribuir y paralelizar el procesamiento entre distintos nodos, como garantizar la tolerancia a fallos si cae algún nodo.
Otros puntos clave en el rendimiento de Vertica y que veremos a continuación son:
· Capacidad de mantener distintas proyecciones para los mismos datos, haciendo que se almacenen tal y como se van a consultar.
· Dos zonas de almacenamiento, la primera optimizada para escritura cuando los datos son más recientes y susceptibles de modificación, y otra optimizada para lectura, donde se moverán los datos ya consolidados.
· Particionamiento de tablas. Es posible particionar físicamente las tablas a lo largo del tiempo en función del valor de un atributo de tipo temporal, de manera que la información se almacenará en la partición correspondiente.
La gestión de todos estos conceptos es transparente para el usuario. De hecho, Vertica proporciona una interfaz SQL estándar para la gestión de la información almacenada, lo que facilita la integración con las aplicaciones y sistemas BI y ETL existentes.
Arquitectura de almacenamiento:
Vertica está diseñado para funcionar en modo distribuido en cluster, distribuyendo el almacenamiento físico y paralelizando las consultas. Pero para comprender mejor como organiza la memoria, consideraremos una arquitectura de un nodo simple:

Igual que en las BD relacionales, las consultas SQL se parsean y optimizan para acceder a la información física. Sin embargo Vertica internamente se organiza en un módelo de almacenamiento hibrido con dos zonas:
· WOS (Write-Optimized Store): Zona de almacenamiento optimizada para escritura. Generalmente alojada en la RAM del sistema y diseñada para resolver de forma eficiente operaciones de tipo INSERT y UPDATE. En esta zona de memoria, la información está desordenada y sin comprimir.
· ROS (Read-Optimized Store): Zona de almacenamiento optimizada para lectura. Contiene el grueso de la información de la base de datos. Almacena los datos comprimidos y ordenados optimizando su lectura.
El proceso encargado de mover información desde la WOS a la ROS se denomina Tuple Mover. Este proceso se ejecuta en segundo plano, y es el encargado de recoger información consolidada en la WOS, ordenarla, comprimirla y almacenarla en la zona ROS, generalmente en disco.
Tanto la WOS como la ROS se organizan en columnas, donde cada columna es un atributo de una tabla. Esto permite acceder físicamente solo a los valores concretos de cada consulta sin tener que leer todos los valores del registro, como se haría en una BD orientada a filas tradicional.
En caso de que un grupo de columnas siempre se lean de modo conjunto, se pueden agrupar para ser recuperadas en una sola operación de lectura a memoria.
Físicamente, la ROS se particiona horizontalmente en varios contenedores. Estos contenedores se organizan por la antigüedad de la información que contienen, el propósito de tener varios contenedores es que el proceso Tuple Mover sea lo más eficiente posible moviendo datos desde la WOS a la ROS. De esta manera, cuando se vuelca información desde la WOS, el Tuple Mover solo tendrá que merguear los nuevos datos con los existentes en primer contenedor por antigüedad y no con todo el grueso de información ya almacenada en la ROS. Periodicamente, el Tuple Mover realiza tareas de consolidación entre los distintos contenedores, moviendo tuplas hacia los que contienen información más antigua y manteniendo el número de contenedores bajo combinando unos con otros y borrando información eliminada, se trata un procedimiento que se podría considerar como de defragmentación de la ROS.

Proyecciones:
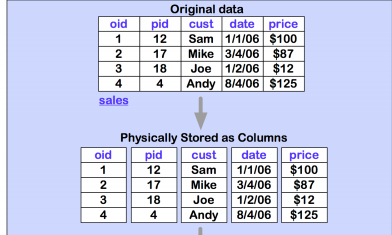
Vertica utiliza Proyecciones para almacenar las columnas en disco, donde cada columna se almacena en una o varias proyecciones.
Una proyección consiste en una agrupación de atributos, almacenados físicamente en disco en un determinado orden. El propósito de esto es acomodar el almacenamiento físico de los datos, a la manera en la que serán consultados. Incluir la misma columna en distintas proyecciones, optimiza la velocidad para resolver consultas en la BD, ya que Vertica resolverá la consulta recuperando la información de la proyección mas optima.
Que una misma columna pueda estar almacenada físicamente en distintas proyecciones supone, evidentemente, tener información redundante en la BD. No obstante como la información se almacena fuertemente comprimida, esta circunstancia no supone un gran problema en comparación con incremento de rendimiento obtenido. Y además reduce la cantidad de información a transferir en cada operación de E/S a disco.

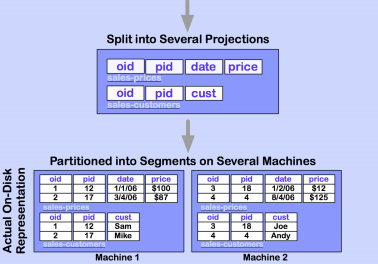
En un entorno distribuido las proyecciones no se almacenan completas en una misma máquina, sino que se particionan horizontalmente en segmentos, que se distribuyen entre las distintas máquinas que componen el cluster, facilitando la paralelización de operaciones, de manera que cada máquina resuelve la operación con los datos que tiene almacenados, bajo el paradigma de llevar el procesamiento a los datos.
Particionado de tablas:
Vertica soporta particionado de tablas, esto permite dividir una tabla en piezas más pequeñas.
Un uso típico de las particiones de tabla consiste en crear particiones organizadas por fecha. Por ejemplo, en una tabla con décadas de información, se pueden crear particiones donde cada partición contenga los datos de un año. Esto permite organizar mejor datos antiguos.
El particionado se aplica a todas las proyecciones de la tabla, y facilita entre otras cosas el borrado de información antigua y mejora el rendimiento de consulta. Por ejemplo, si un contenedor de la ROS almacena información anterior a una determinada fecha, podrá ser borrado en bloque o descartado para los resultados de una consulta.
No hay que confundir el particionado de tablas con la segmentación que se aplica en entornos distribuidos a las proyecciones. El particionado segrega datos de una tabla en diferentes particiones dentro de la misma máquina en función del valor de un atributo de la tabla, su propósito es facilitar el borrado de datos y mejorar el rendimiento de las consultas. Mientras que la segmentación distribuye datos de una misma proyección entre diferentes máquinas, su propósito es distribuir el procesamiento entre los distintos nodos del cluster.
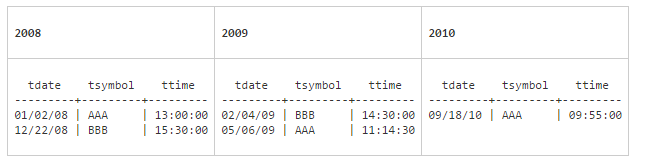
Para definir una partición, el primer paso es determinar la relación entre los datos y las particiones. Para ello consideraremos la siguiente tabla:

Si queremos agrupar datos por año, lo lógico es definir particiones de un año, quedando la tabla particionada del siguiente modo:
Esto se consigue mediante el DDL y la clausula PARTITION BY EXTRACT(year FROM tdate). Pej en una sentencia CREATE TABLE:

Una vez definidas las particiones de una tabla, el proceso Tuple Mover se encarga al pasar datos de la WOS a la ROS de enviar los datos a la partición correspondiente y de modo transparente, Vertica se encarga de optimizar operaciones.
Asimismo, Vertica proporciona operaciones para que el usuario pueda realizar operaciones sobre las particiones de una tabla:
· Borrado: Libera el espacio de almacenamiento de la partición indicada.
· Hacer swapping entre particiones: Mover particiones concretas de una tabla a otra tabla, borrando las particiones movidas en la tabla original
· Reorganizar particiones: Modificar mediante una sentencia ALTER TABLE los criterios de definición de la partición, de manera que la información previamente almacenada en las particiones existentes, se mueve a las nuevas particiones.
· Copiar particiones concretas de una tabla a otra.
· Restaurar particiones.
Configuración del proceso Tuple Mover:
El proceso encargado de mover información de la WOS a la ROS admite cierta configuración. Los parámetros relacionados con los conceptos vistos son:
· ActivePartitionCount: Número de particiones activas por tabla. Por defecto se considera que solo la partición más reciente de una tabla está active, de manera que solo se recibirán datos destinados a dicha partición, si no es así este parámetro establece cuantas particiones estarán activas.
· MergeOutInterval: Intervalo en segundos para que el Tuple Mover realice tareas de consolidación entre contenedores en la ROS para evitar que el número de estos crezca mucho.
· MoveOutInterval: Intervalo en segundos para mover información de la WOS a la ROS.
HP Vertica for SQL on Hadoop
Permite construir una BD Vertica sobre HDFS. La licencia no impone límite de almacenamiento.
Se trata de un modelo de despliegue donde los nodos de Vertica se despliegan sobre los nodos de un cluster Hadoop o al menos en un subconjunto de ellos, de manera que los dos sistemas coexisten sobre las mismas máquinas.
Los nodos de Vertica crean una red privada para los procesos propios de la BD, separada de la red utilizada por los procesos de Hadoop.
La conexión entre Vertica y HDFS se puede conseguir de 4 modos distintos:
· Creando un almacén de datos nativo sobre HDFS: Permite a Vertica disponer de su propia copia de la ROS en formato nativo, aparte de disponer una copia en HDFS. Proporciona un mayor rendimiento ya que las consultas se resuelven sobre la copia nativa, pero necesita mayor capacidad de almacenamiento para mantener la duplicidad en ambos formatos.
· Utilizando un lector ORC (Optimized Row Columnar): Permite acceder a datos almacenados en Hadoop en formato ORC file format, Vertica puede consultarlos directamente desde HDFS. Sin embargo no permite definir nuevos esquemas
· Utilizando el conector HCatalog. Permite utilizar los servicios de Hive para consultar datos y definir esquemas, sin embargo ofrece peor rendimiento.
· Utilizando el conector HDFS. Permite definir nuevos esquemas sin disponer de las ventajas de Hive, el formato de las tablas tiene que ser definido por el propio usuario.
Otras características interesantes de Vertica son:
· Dispone de herramientas de diseño automático de bases de datos: Permiten analizar el esquema lógico de la base de datos, así como las consultas más frecuentes para realizar el diseño físico mas optimo mediante la definición de las proyecciones necesarias.
· Dispone de herramientas de monitorización y administración, gestión de backups y disaster recovery.
· Integración con HP Distributed R.
· Apis en Java y C++ para extender Vertica e integrarlo a bajo nivel con nuestras aplicaciones.
· Alto rendimiento.
· ACID.
· Compatible con varias distribuciones Linux + distribución en appliance en servidores HP BladeSystem.

Deja un comentario