

Tajoes un es un datawarehouse sobre Hadoop que permite lanzar queries SQL con baja latencia sobre grandes data-sets en HDFS y otras fuentes de datos. Dicho de otra forma sería otra alternativa a Impala, Stinger, Dremel, Presto,…
Sus principales características (algunas ciertamente interesantes) son:
· Escalabilidad y baja latencia
o Tiempo de respuesta muy bajo(100 msec ~) para queries sencillas (agregación, joins) sobre tamaños “razonables”
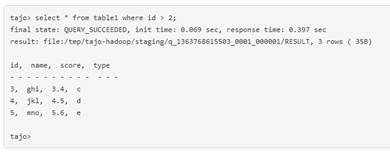
· Soporte ejecución de queries de larga duración
o Tolerancia a fallos que permite no tener que reiniciar la query cuando algo falla (algo que Impala por ejemplo no da)
· ETL
o Características ETL que permite transformar de un format de datos a otros, soportando formatos como CSV, RCFile y RowFile
· Extensible
o Permite definir funciones al usuario
· Compatibilidad
o ANSI/ISO SQL standard compliance y compliance PostgreSQL para partes no estándar
o Modo con soporte HiveQL
o Acceso a tablas sobre Hive Metastore y HCatalog
o JDBC driver support
· Sencillez
o Consola interactiva
o Utilidad Backup/Restore
o API Java síncrona/asíncrona para enviar queries a los clusters Tajo
o Interactive shell to allow users to submit SQL queries to Tajo clusters
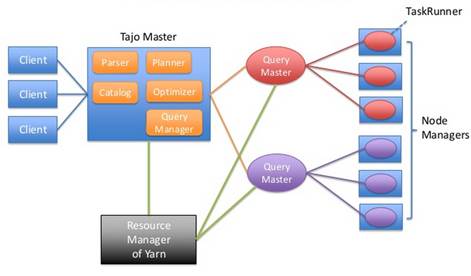
La Arquitectura de Tajo es esta:
Más allá de sus características me parece interesante es que sea una iniciativa no vinculada a ningún proveedor.
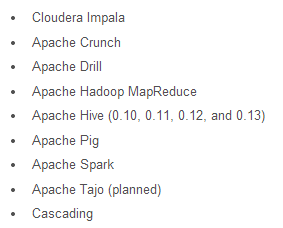
Las próximas versiones de Cloudera lo llevarán integrado, junto a:
Podéis leer algo más sobre Tajo en:

Deja un comentario