

Ha pasado ya más de medio año desde que me “pegué” con Apache Kafka (y nunca mejor dicho)…y lo cierto es que con el tiempo le voy cogiendo cariño (bueno, no sé si esa es la palabra :D).
En su momento probé la versión 0.7 y las impresiones fueron algo negativas.
La nueva versión, la 0.8 aún sigue en beta pero añade conceptos y funcionalidades que hacen casi olvidar sus deficiencias (documentación inexistente, scripts, incompatibilidades entre versiones,…)
Kafka ya sabemos que es un sistema distribuido y particionado de mensajería.
Conceptos
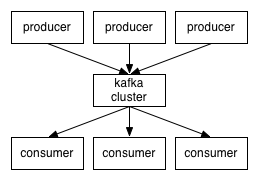
· Kafka mantiene los mensajes en categorías llamadas Topics.
· Productores publicar mensajes en un Topic Kafka.
· Los consumidores se suscriben a los Topics y reciben los mensajes publicados en estos Topics.
· Kafka se ejecuta como un cluster de uno o más servidores de cada una de los cuales se llama Broker.
Características:
· Rápido: Un único Broker de Kafka puede manejar cientos de megabytes de lecturas y escrituras por segundo desde miles de clientes.
· Escalable: Kafka está diseñado para permitir que un solo cluster sirva como el eje central de datos para una organización grande. Puede ser ampliado elásticamente sin tiempo de inactividad. Los flujos de datos se dividen y se extiende sobre un cluster de máquinas para permitir que los stream de datos sean más grande que la capacidad de una máquina
· Duradero: Los mensajes se persisten en disco y se replican dentro del clúster para evitar la pérdida de datos. Cada Broker puede gestionar terabytes de mensajes sin impacto.
· Distribuido: Kafka cuenta con un diseño de cluster-centric que ofrece durabilidad y garantías de tolerancia a fallos.
Estilo de Mensajería:
Los sistemas de mensajería tradicional tienen 2 modelos: Queues (P2P) y Topics (Publish-Suscribe).
En una cola (Queue) cada mensaje va a un consumidor, mientras que en un topic (PS) se hace broadcast de un mensaje a todos los consumidores.
Kafka ofrece una abstracción que permite contemplar ambos modelos: el consumer group
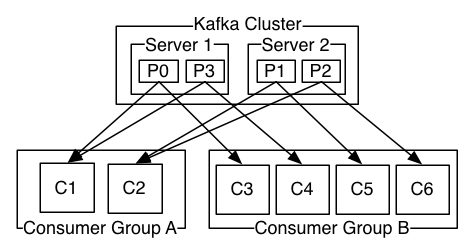
Los consumidores se identifican con un consumer group, cada mensaje publicado a un Topic en Kafka es enviado a una única instancia dentro de un consumer group.
De este modo si todas las instancias de consumidores tienen el mismo consumer group funciona como un Sistema de Colas (Queue), mientras que si cada instancia tiene un consumer group funciona como un Sistema Publish-Suscribe.
Anatomía de Tópicos: Particiones
· En Kafka los Tópicos se organizan en particiones, que son secuencias de mensajes ordenados e inmutables. Los mensajes en una partición tienen asignado un número secuencial llamado offset que identifica cada mensaje en una partición (esto permite que rendimiento sea constante)

· Las particiones se distribuyen sobre los servidores del cluster Kafka, de modo que cada Servidor se encarga de manejar los datos y peticiones a una parte de las particiones.
· Las particiones se replican a un número configurables de servidores para tolerancia a fallos (recomendado 3 como HDFS)
· Las particiones permiten que el tamaño de un Tópico sea mayor que la capacidad de un Servidor, cada partición individual debe caber en el servidor que lo almacena pero un tópico está formado por varias particiones.
· Cada partición tiene un Servidor que actúa como Líder (leader) y 0 o más Servidores que actúan como Seguidores (followers).
· El leader maneja todas las peticiones de lectura y escritrura para una partición mientras que los followers replican al leader pasivamente.
· Si el leader falla uno de los followers automáticamente se convierte en el nuevo leader.
· Cada Servidor actúa como Leader para algunas de las particiones y como follower para otras de modo que la carga se balancee correctamente en el cluster.
· El cluster Kafka mantiene todos los datos publicados (sean consumidos o no) por un tiempo configurable.
Sincronización entre Clusters
· Un Cluster Kafka no está pensado para estar distribuido entre datacenters, el soporte para escenarios multi-datacenter en Kafka se da a través del mirroring entre clusters.
· Esta característica permite que el cluster mirror actúe como consumidor del cluster fuente.
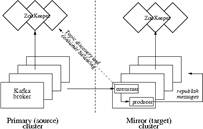
· Esto permite que un cluster pueda consumir datos de varios datacenters
· Kafka ofrece una herramienta para esto: https://cwiki.apache.org/confluence/display/KAFKA/Kafka+mirroring+(MirrorMaker)
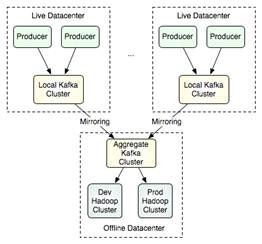
· Este escenario permite topologías como la mostrada en la que existe un cluster mirror que recibe información de varios clustes Kafka y la almacena en Hadoop:
Rendimiento
Kafka tiene un diseño en el que se prima el rendimiento sobre las características.
Existen diversas métricas de rendimiento, a mí me parecen representativas estas:
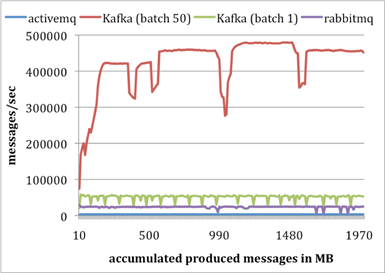
O esta:

En la que se ve como Kafka consume a 22K mensajes/segundo, más de 4 veces más rápido que ActiveMQ y RabbitMQ.
APIs
Publisher:

Consumer:


Deja un comentario