
Ya hemos dedicado algunos post a Storm, el framework para procesamiento de streams de datos Big Data, capaz de soportar millones de
https://unpocodejava.wordpress.com/2012/07/26/cuando-hadoop-no-es-suficientemente-rapido/
https://unpocodejava.wordpress.com/2012/09/17/storm-el-hadoop-para-procesar-streams/
Hoy quería hablar sobre Trident, que es en esencia una abstracción de alto nivel sobre Storm para realizar computación en tiempo real.
Con Trident se puede manejar un alto throughput (millones de mensajes por segundo) y realizar un procesamiento de streams stateful con queries distribuidas de baja latencia.
Estas palabras acercan aún más Storm a un CEP Big Data!!!
Si comparamos Storm con Hadoop Trident sería el Pig o el Cascading.
Trident permite:
- JOINS, AGREGACIONES, GROUPS, FUNCIONES Y FILTROS
- Añadir primitivas para realizar procesamiento incremental con estado sobre cualquier store persistente
Veamos algún ejemplo ilustrativo:
Primero tenemos un generador (Spout) infinito (Cycle) de streams de sentencias:
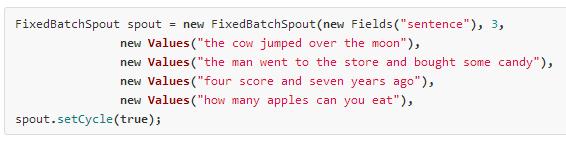
En un ejemplo real las entradas podrían ser colas Kafka o Kestrel.
Una topología Trident que contase las palabras de las sentencias que van llegando sería como esto:

Trident procesa los streams como pequeños batchs separándolo en algo como:
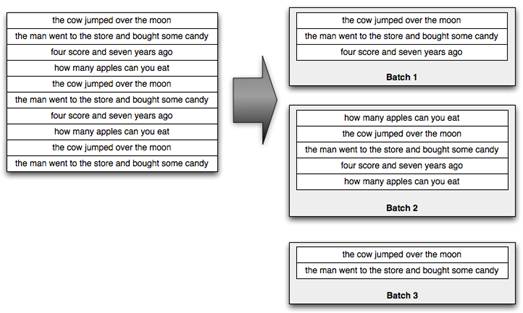
Los resultados del agregado pueden persistirse a una base de datos o bien usar por ejemplo Memcached con la integración que ofrece Trident.

Las topologías Trident compilan en topologías Storm lo más eficientes posible, las tuplas sólo viajan por la red cuando se realizar un particionado (como por un groupBy).
Por ejemplo esta topología Trident:
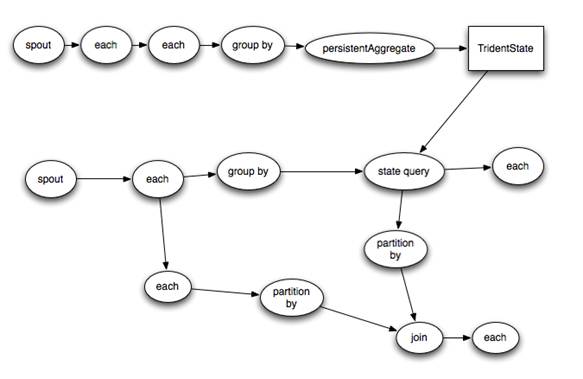
Compilaría en esta topología Storm:
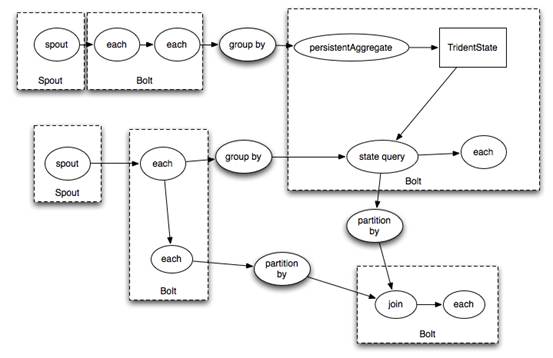
Lo único que echo en falta a Trident es un lenguaje declarativo (y no con API Java) para definir las consultas.

Deja un comentario