

(Je,je, ahí va Luis, para que lo añadas a los productos a probar :D)
Fluentd es una librería open source que actúa como colector de logs tratándolos como streams JSON y enviándolos a otros sistemas como S3, MongoDB, Hadoop o otros Fluentds.
Fluentd recoge eventos de varias input sources y lo escribe a output sinks como:
· Input: HTTP, Syslog, Apache Log
· Output: Files, Mail, RDBMS, NoSQL storages
Fluentd está escrito en C y tiene un wrapper Ruby.
Su arquitectura está enfocada al procesamiento en entornos “Big Data”, y tienes instalaciones de más de 500 servidores generando 5 TB diariamente y con 50000 mensajes/segundo.
Lo usan por ejemplo en Slideshare para streaming de logs y eventos en la nube (otros clientes).
Entre sus principales características:
· Fácil instalación: disponible como RPM, DEB y Ruby Gem sin dependencias.
· Footprint pequeño: el core de Fluentd son 3000 líneas Ruby.
· Logging de datos semiestructurados: un evento consta de 3 componentes: tag, time y record. Tag es cadena separada por . (myapp.access) para categorizar eventos, time en formato UNIX y record es el objeto JSON.
· Plugins de entrada y de salida como (in_http, in_tail, out_mongo, out_webhdfs,…)
· Logging desde numerosos lenguajes (incluido claro está Java)
· Mecanismo Flexible de Plugins:
· Buffering confiable
· Log Forwarding
· Configuración en Alta Disponibilidad: http://docs.fluentd.org/articles/high-availability
Para empezar os recomiendo su Quickstart Guide.
Si como yo trabajáis en Java usarlo en muy sencillo:
· Configuráis librería en Maven:

· Creáis un FluentLogger:
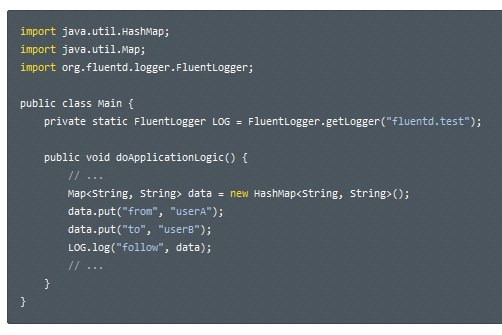
· Configuráis fluentd:
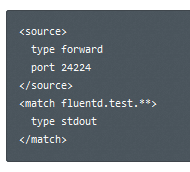
· Reiniciais el agente de Fluentd:

En su documentación aparecen descritos en detalle algunos escenarios interesantes como:

· Almacenamiento de Logs de Apache en MongoDB


Deja un comentario