
(Este va para ti Santos, a ver si consigo que alguna vez leas algo :P)
Tranquilos, que no me voy a atrever aquí a hacer una exposición de la obra de Kafka (aunque recuerdo que la lectura en la juventud de La Metamorfosis me impactó :))…me refiero a Apache Kafka:
Apache Kafka es un sistema de mensajería Publish-Suscribe distribuido. (https://unpocodejava.wordpress.com/2012/10/30/linkedin-kafka-streaming-segun-linkedin/)
Está diseñado con estos objetivos:
- Mensajería persistente a estructuras de disco O1 que proporcionan un rendimiento constante en el tiempo, incluso con varios TB de mensajes almacenados.
- Alto rendimiento: incluso con hardware muy modesto Kafka puede soportar cientos de miles de mensajes por segundo.
- Soporte para la partición de mensajes a través de los servidores de Kafka y consumo distribuido en un cluster de máquinas consumidores, manteniendo la ordenación por partición
- Soporte para la carga de datos en paralelo en Hadoop.
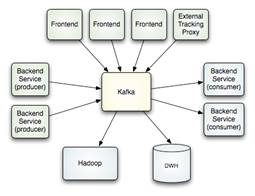
Kafka pretende unificar el procesamiento online y offline, proporcionando un mecanismo para la carga paralela en Hadoop, así como la capacidad de partición en tiempo real del consumo en un cluster.
Podéis ver una métricas de cómo el rendimiento no se ve afectado cuando se incrementa el número de consumidores, tópicos,… aquí.
El uso para el procesamiento de streaming lo hacen comparable a Scribe Facebook o Apache Flume (incubación), aunque las arquitecturas son muy diferentes y es más fácil ver Kafka como un sistema de mensajería tradicional.
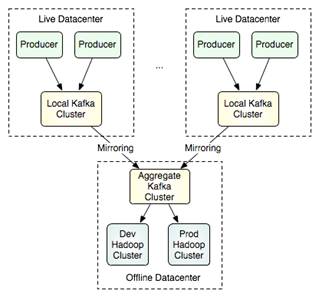
La Arquitectura de Kafka no pretende que un único cluster gestiona varios data centers, si no para soportar una topología multi-datacenter.
Para esto permite el mirroring o "sincronización" entre los cluster de una forma muy sencilla: el clúster espejo simplemente actúa como un consumidor de la fuente de clúster. Esto significa que es posible que un solo grupo para unir datos de muchos centros de datos en un solo lugar. Un ejemplo sería:
Si os pica la curiosidad podéis empezar con su Quick Start.

Replica a Auto-links sobre sobre Big Data | Un poco de Java Cancelar la respuesta