

Hystrix es una librería Java diseñada para controlar las interacciones entre servicios distribuidos proveyendo mayor latencia y tolerancia a fallos.
Para eso Hystrix aislando los puntos de acceso entre los servicios, parando los fallos en cascada a través de ellos y proporcionando opciones de fallback, lo que hace que se mejore la resistencia global del sistema.
Hystrix parte del trabajo del equipo de ingeniería de Netflix API de 2011, en el 2012, Hystrix ha seguido evolucionando y madurando, adoptándose por muchos equipos dentro de Netflix.
Hystrix gestiona al día decenas de miles de millones de hilos aislados y cientos de miles de millones de llamadas de semáforos aislados mejorando el tiempo de actividad y la resistencia.
Si aún no veis lo que nos permite Hystrix pensemos en una aplicación que depende de 30 servicios cada uno con una disponibilidad del 99,99%:
99.99 30 = tiempo de actividad del 99,7%
al 0,3% de 1 mil millones de peticiones = 3.000.000 fallos
Más de 2 horas de tiempo de caída por mes
(aunque ya sabemos que la realidad sería peor aún :)):
El problema:
En un escenario correcto el flujo de una petición sería:
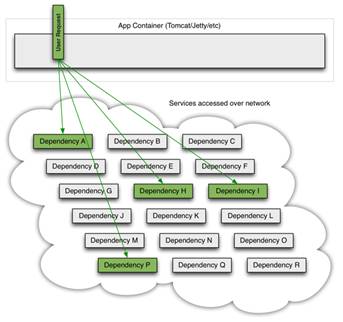
Pero si sólo uno de los sistemas se ralentiza esto puede bloquear la petición entera del usuario.
Además con un gran volumen de tráfico una única dependencia puede hacer que todos los recursos se saturen en segundos en todos los servidores:
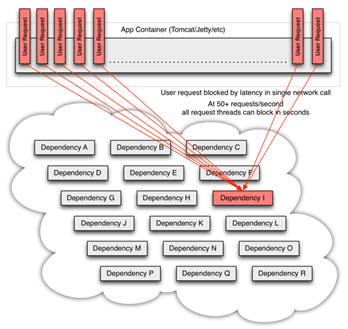
Estos problemas pueden agravarse más cuando el acceso se realiza por terceras partes o cuando las configuraciones son diferentes para cada dependencia y son difíciles de monitorear y cambiar.
Los objetivos a conseguir por Hystrix
· Restringir el uso de User Threads en contenedor (como Tomcat)
· Fallo rápido en lugar de encolar
· Proporcionar mecanismos de fallback siempre que sea posible proteger a los usuarios del error
· Usar técnicas de aislamiento (como swimlane) para limitar el impacto de cualquier dependencia de uno.
· Optimizar tiempo de descubrimiento a través de métricas en tiempo real, monitoreo y alertas
· Optimizar tiempo de recuperación permitiendo el cambio de configuración dinámica en en los aspectos de Hystrix
Cómo consigue esto Hystrix:
· Actúa como wrapper de todas las llamadas a sistemas externos (dependencias) en un objeto HystrixCommand (command pattern) que normalmente se ejecuta en un subproceso independiente.
· Timeout en llamadas que requieren más tiempo que los umbrales definidos. Existe un valor por defecto y se puede configurar
· Mantener un pequeño Thread Pool para cada dependencia y si se llena comandos completos serán inmediatamente rechazarlos en lugar de encolados.
· Medir las ejecuciones correctas, errores, timeouts e hilos rechazados
· Ofrecer un interruptor que permite manualmente o automa´ticamente parar todas las peticiones a un servicio por un periodo de tiempo si el porcentaje de errores supera un umbral
· Realizar lógica de fallback cuando la petición falla
· Controlar las estadísticas y el cambio de configuración en tiempo casi real.
Cuando se usa Hystrix para envolver cada dependencia subyacente la arquitectura se comporta así:
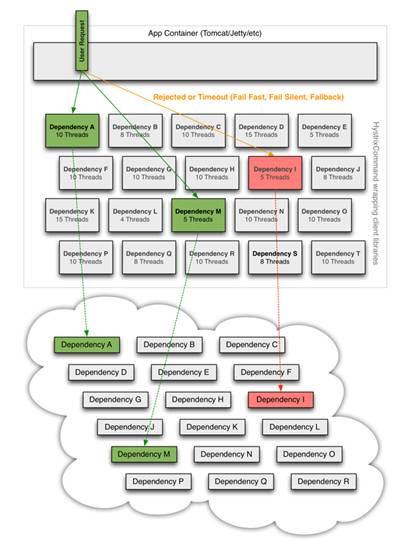
¿Cómo se usa?
Cualquier lógica de negocio debe ser wrapeada a través de un HystrixCommand.
El Hello World sería:

Los comnados de Hystrix se ejecutan de forma síncrona con:
![]()
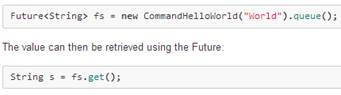
Y de forma asíncrona:
Fallback:
Para controlar la degradación correcta se implementa un método getFallback () que se ejecutará para cualquier tipo de fallo: run(), tiemout, pool,…


Deja un comentario