
Tess4J es una librería Java open-source con licencia Apache, que actúa como Wrapper JNA para la librería OCR open-source Tesseract.
Usarla es muy sencilla, veamos un ejemplo.
Primero creamos un proyecto Maven con el arquetipo quickstart.
mvn archetype:generate -DgroupId=com.indracompany.examples.tess4j -DartifactId=tess4j-example -DarchetypeArtifactId=maven-archetype-quickstart -DinteractiveMode=false
Luego añado a mi pom.xml:
<dependency>
<groupId>net.sourceforge.tess4j</groupId>
<artifactId>tess4j</artifactId>
<version>3.2.1</version>
</dependency>
Y genero el proyecto de Eclipse con >mvn eclipse:eclipse:
Luego en https://github.com/tesseract-ocr/tessdata descargaré los datos entrenados para los lenguajes que me interesen:
· Inglés à https://github.com/tesseract-ocr/tessdata/blob/master/eng.traineddata
· Español à https://github.com/tesseract-ocr/tessdata/blob/master/spa_old.traineddata (bajaros este y renombradlo a spa.traineddata.
Luego en mi proyecto creo la carpeta tessdata donde dejo los ficheros traineddata descargados:
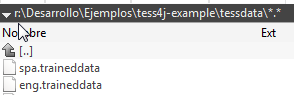
Para acabar creo una carpeta images y dejo la imagen/imágenes de las que quiero hacer OCR:
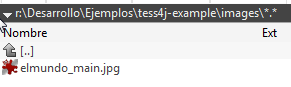
(en mi caso con la extensión de Chrome Full Page Screen Capture he generado como imagen la web principal de elmundo.es):
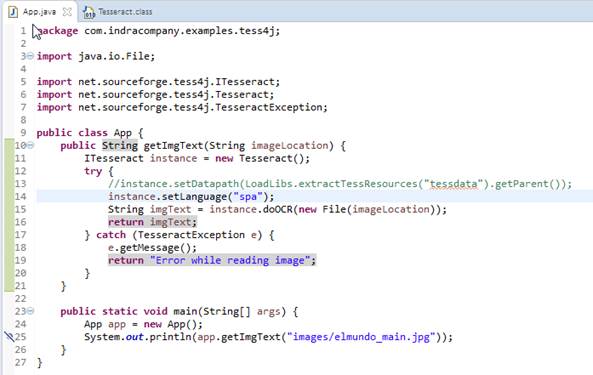
Para acabar en la clase Java App.java que ha generado Maven dejo este código:
Si ejecutamos el código obtendré algo como esto:

Si me fijo en el texto de este banner que compone la imagen:

Podemos ver como el OCR ha obtenido:

Podemos probar a usar el lenguaje por defecto (inglés), con comentar esta línea:
![]()
en este caso habríamos obtenido:

tess4j y su librería OCR Tesseract puede configurarse y entrenarse para obtener mejores resultados (pero eso es otro post 🙂 ).

Deja un comentario