

Apache Flink es una Plataforma Open Source para procesamiento de Streams (como Storm o Spark Streaming) y de Batch en el ámbito Big Data.
Sus principales características son
· Rapidez: con su procesamiento streaming hablan de un rendimiento bastante superior al referente en este ámbito: Storm:
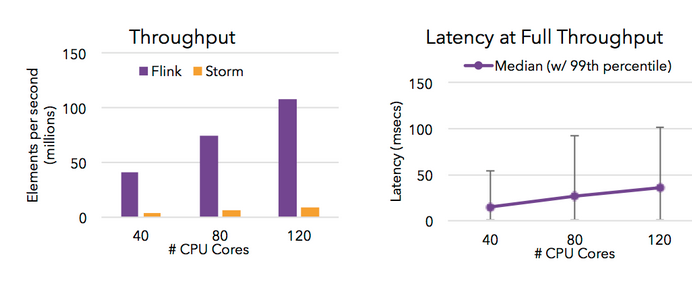
· Confiable
· Escalable: testado en clusters de cientos de máquinas
· Compatible con Hadoop: correo sobre YARN y HDFS, una gran ventaja sobre Storm (aunque ya pueda correr sobre YARN)
· Fácil de usar: otra gran ventaja sobre Storm
· Usable en Java y Scala: para mí imprescindible 😀
Para hacernos una idea de cómo funciona veamos el Hola Mundo en este ámbito, el Contador de Palabras:
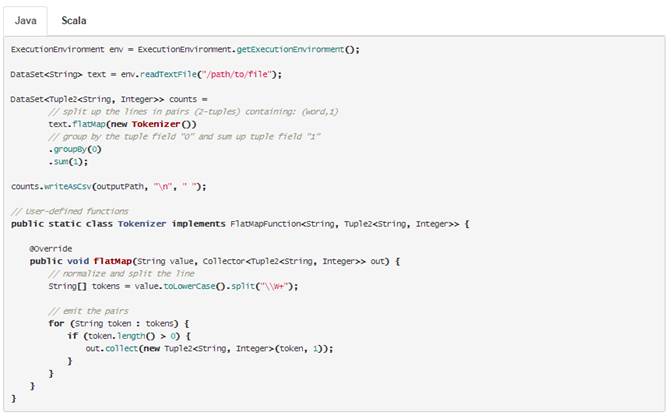
Como veis crea un Tokenizer que sobre el fichero de entrada genera una salida por cada palabra con la palabra y un 1, sobre este resultado se hace una agrupación (groupBy) por el primer campo (la palabra) y suma por el segundo campo (el 1).
El Stack de Flink se compone de:
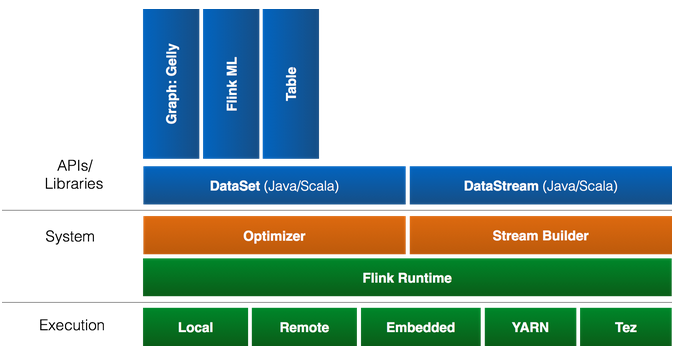
Donde se ofrecen diversas APIS:
1. DataSet API para procesamiento Batch, con APIs en Java, Scala, y Python
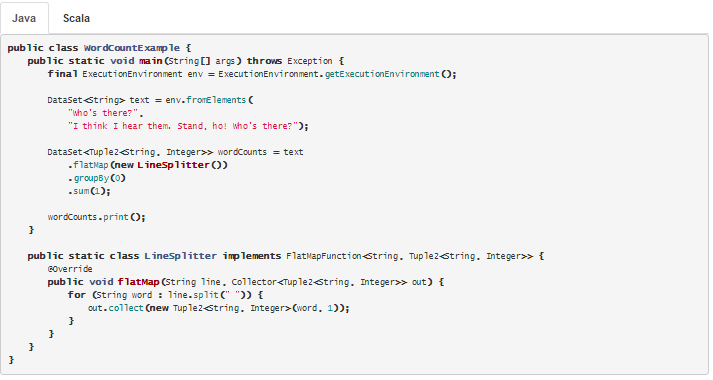
- DataStream API para procesamiento en Streaming en Java y Scala:
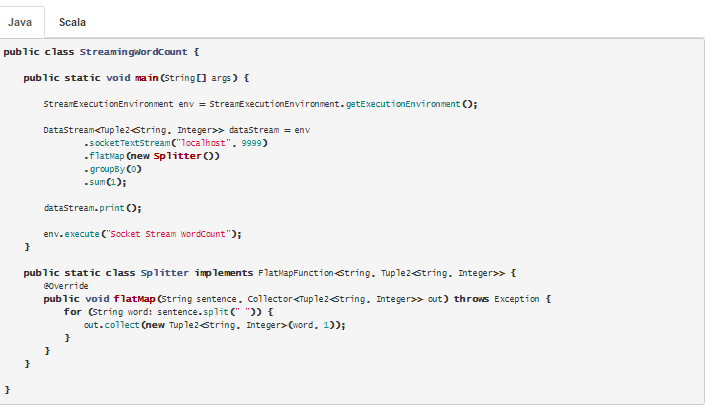
En este ejemplo se cuenta en tiempo real las palabras que se van recibiendo por un WebSocket
- Table API muy interesante es este lenguaje embebido SQL-like en Java y Scala:

A nivel de Sistema Flink cuenta con:
· Exactly-once Semantics for Stateful Computations
· One Runtime for Streaming and Batch Processing
· Memory Management: Flink tiene su propia gestión de la memoria dentro de la JVM
· Iterations and Delta Iterations
· Program Optimizer
Además de esto Link incluye librerías para:
· Machine Learning vía FlinkML

Para operarlo Flink cuenta con:
· Scala Shell interactivo:
· Cliente Web que permite cargar Jobs, ver planes de ejecución y ejecutarlos.
La última versión es la 0.9, de junio de 2105

Deja un comentario