
Continuando con el post de ayer:
MongoDB Connector for Hadoop: MongoDB y Hadoop uniendo fuerzas!
Conforme a este documento hoy veremos algunos casos de uso típicos en los que MongoDB y Hadoop pueden formar un stack Big data típico.
En estos MongoDB actúa como el datastore en tiempo-real/operacional t Hadoop como el datastore offline para procesamiento y análisis.
Agregación Batch
En muchos escenarios la funcionalidad de agregación incluida en MongoDB es suficiente para analizar los datos, cuando es necesario un análisis más complejo Hadoop nos provee un framework muy potente para análisis complejos:
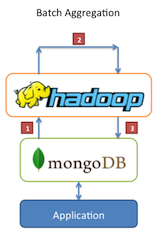
En este escenario los datos se extraen de MongoDB y se procesan en Hadoop con uno o más jbos MapReduce.
La salida de estos Jobs puede ser de nuevo escrita en MongoDB para consultas posteriores.
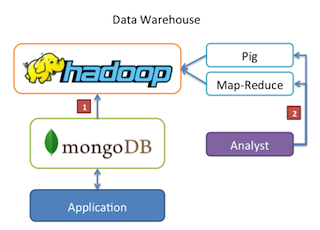
Data Warehouse
En un escenario típico de producción los datos del sistema pueden estar en diferentes datastores cada uno con su lenguaje de queries,…
Hadoop en este escenario puede usarse como datawarehouse y repositorio centralizado de múltiples fuentes lo que simplifica la complejidad de tratamiento de estos datos.
Pueden usarse Jobs MapReduce periódicos que vuelcan datos de Mongo a Hadoop.
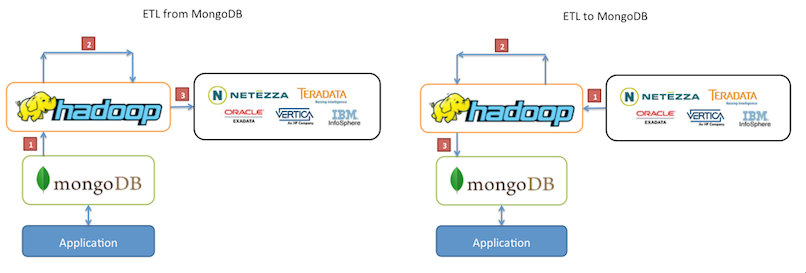
ETL Data:
MongoDB puede ser el datastore operacional de nuestra aplicación pero también puedex existir otros. En este escenario es útil mover datos de un datastore a otro.
Los Jobs MapReduce pueden usarse para extraerse, transformar y cargar datos de un datastore a otro, actuando Hadoop como una ETL.

Deja un comentario