

Apache Spark™ es un motor distribuido para procesar grandes volúmenes de datos.
El equipo de Spark promete ser 100 veces más rápido que un trabajo MapReduce Hadoop en memoria o 10x veces más rápido que un trabajo MapReduce en disco.
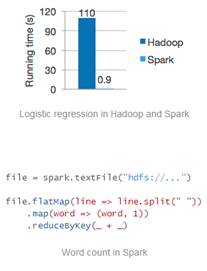
Seguro que ya os estáis haciendo la pregunta de ¿Y Hadoop?
Spark no usa el framework MapReduce de Hadoop pero si puede correr sobre clusters YARN (Hadoop 2) y leer cualquier tipo de dato Hadoop (HDFS, HBase, Cassandra,…).
De hecho Spark se ejecuta sin instalación sobre cualquier cluster Hadoop 2 (y puede instalarse en EC2 por ejemplo).
Puede desarrollarse en Java, Python o Scala.
Los que conozcáis el API MapReduce de Hadoop podéis ver las grandes diferencias entre ambos:

Este ejemplo cuenta el número de líneas conteniendo el texto “a” y el número de líneas conteniendo el texto “b”. Imaginaros como sería en MapReduce 😀
Aquí podéis encontrar las guías del desarrollador para Java, Scala y Python.
En su web podéis encontrar varios tutoriales, ejemplos, videocasts,..
Para empezar podéis .
Y seguiréis aún preguntándoos: ¿Debería salir del framework ofrecido por Hadoop?
Una de las ventajas de Spark frente a otras soluciones es que ofrece herramientas de alto nivel para un gran número de escenarios:
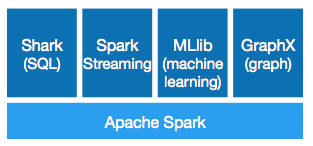
Mi opinión es que en este cambiante y creciente ecosistema de Hadoop aún es muy pronto para adoptar Spark para un sistema/solución de amplio recorrido, ya que existen soluciones que aunque menos integradas nos ofrecen toda esta funcionalidad sobre un contenedor estándar, aunque es una solución para tener en el punto de mira por si finalmente se convierte en uno/otro estándar en el mundo del Big Data open-source!!!
Veamos que ofrecen estas tolos de Spark:
![]()
Shark es un motor de consultas SQL distribuido open-source que opera sobre el metastore y el cliente de HIVE.
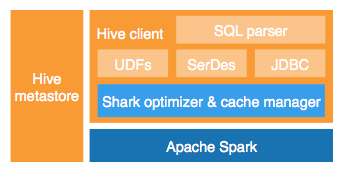
Esto le permite ejecutar queries HIVE sin modificar con incrementos de velocidad de hasta 100x veces.
Frente a otras opciones (Impala, Stinger, Presto, Tajo,…) está su integración transparente sobre Spark.
En el desarrollo de Spark están participando grandes empresas como Intel, Yahoo, Webtrends, Groupon,…

Spark Streamingpermite con el API de Spark escribir aplicaciones que procesan streams de la misma forma que escribes job batch. Se pueden escribir en Java y Scala.
Ofrece semántica de procesado sólo una vez y recuperación ante erorr.
Si veis el API os recordará a Storm, de nuevo la ventaja es la integración transparente:
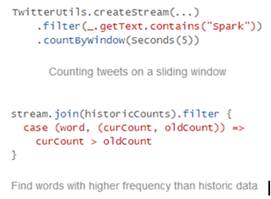
Un ejemplo sencillo e interesante: http://www.pwendell.com/2013/09/28/declarative-streams.html

MLlibpermite con el API de Spark desarrollar trabajos de Machine Learning, permitiendo trabajar sobre cualquier fuente Hadoop (HDFS, HBASE,…)
Los algoritmos prometen ser hasta 100 veces más rápidos que con MapReduce.
Los algoritmos incluidos son:
- K-means clustering with K-means|| initialization.
- L1- and L2-regularized linear regression.
- L1- and L2-regularized logistic regression.
- Alternating least squares collaborative filtering, with explicit ratings or implicit feedback.
- Stochastic gradient descent.
GraphX
GraphXextiende el API de colecciones distribuidas tolerante a fallos de Spark con un API de grafos que permite construir, transformar y razonar sobre datos en grafo de modo escalable.

Deja un comentario