
A Storm ya le hemos dedicado varios posts en el Blog, pero a S4 nos lo despachamos con un escueto “Storm garantiza que cada mensaje se ha procesado por completo, S4 no lo garantiza“ en este post: https://unpocodejava.wordpress.com/2012/07/26/cuando-hadoop-no-es-suficientemente-rapido/
El caso es que Luis no estaba convencido, y efectivamente cada uno tiene sus ventajas e inconvenientes…echémosle un ojo:

DISTRIBUCIÓN DEL TRABAJO:
| S4 | STORM |
| -Trabajo se distribuye uniformemente entre los nodos
-Cualquier nodo puede hacer cualquier trabajo -El trabajo se parelizar con event-keys: si sólo hay una event-key sólo existirá un PE (Processing Element) |
-Usuario define una topología y un mapeo en tareas
-Cada spout y bolt se replica un número de veces decidiso por el usuario -Tareas se distribuyen de forma uniforme entre máquinas disponibles |
TOPOLOGÍAS:
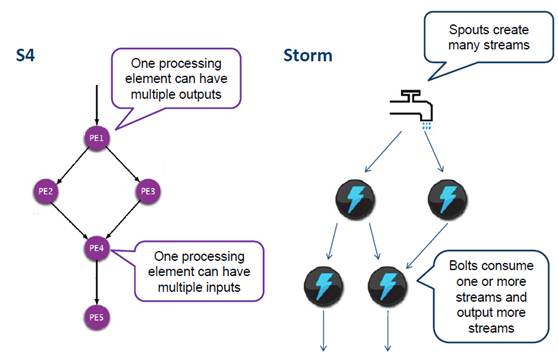
CONFIGURACIÓN
| S4 | STORM |
| Spring:
|
Java TopologyBuilder:
|


OTRAS CARACTERÍSTICAS
| S4 | STORM |
| -Comunicación con Cliente: JSON | -Comunicación con Cliente: Spouts definidos por usuario
-Interface de administración y carga |
TABLA RESUMEN:
| S4 | STORM |
| +Conceptualmente más potente
+Programación más sencilla +Recuperación del estado +Balanceo de carga automático +Construido comunicación con cliente -Configuración compleja -Procesamiento Opaco -Potencialmente pueden perderse datos -Complicado de depurar -En incubación en Apache -Comunidad poco activa |
+Garantiza procesamiento
+Distribución automática de tareas +Debugging sencillo (Local Topology) +Comunidad muy activa +Alto rendimiento +Mayor control +Soporta programación con threads +Funcionalidades avanzadas: Trident, topologías transaccionalidad +Ecosistema -No tiene balanceo de carga automático -Mucho trabajo para el desarrollador -En desarrollo |

Deja un comentario