
Ahora que el primer post que dedicamos a Hadoop hace un año (y aprovechando la documentación de la gente de Pivotal) recordemos las bases de Hadoop: HDFS en este caso.
Apache Hadoop tiene 2 componentes principales:
· Almacenamiento distribuido
· Computación distribuida
El almacenamiento distribuido lo proveé HDFS (Hadoop Distributed File System) que ofrece un almacenamiento escalable, tolerante a fallos, soportado sobre HW commodity,…
La Arquitectura de HDFS se basa en dos piezas: Namenode y Datanode:
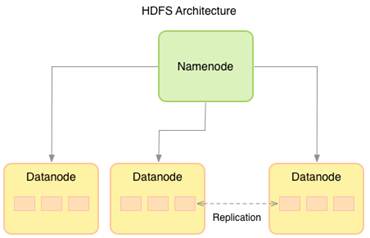
· HDFS almacena los ficheros partiéndolos en bloquees (por defecto de 64 MB). Con esto se consigue minimizar el coste de las búsquedas.
· HDFS usa una arquitectura Master-Slave donde el maestro es el NameNode que se encarga de gestionar los ficheros y los metadatos.
· Estos metadatos contienen información sobre el fichero, bloquees y la localización de estos en los DataNodes.
· Los DataNodes tienen la responsabilidad de almacenar y recuperar los bloques
· Los DataNodes forman un cluster donde los bloquees se replican (por defecto 3 veces) sobre los DataNodes para garantizar la tolerancia a fallos
La carga de un fichero en HDFS funciona de esta forma:
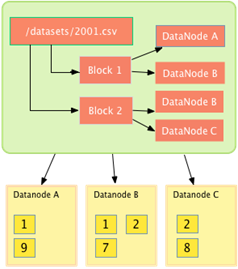
Viendo esta Arquitectura está claro que el NameNode es un Single Point of Failure. Por suerte Hadoop 2.0 incluye alta disponibilidad del NameNode, suministrada por ZooKeeper.

Deja un comentario