
Storm se ha convertido en un standard de facto para el procesamiento en tiempo real de grandes cantidades de información (Big Data) así como Hadoop lo hizo para el modo batch.
Las dudas nos pueden llegar a la hora de elegir la alimentación de los Spout de Storm para que resulte una solución robusta y escalable. Seguramente ya nos fiamos de Storm para el procesamiento, pero la recolección de los datos requiere poner en escena otras herramientas para obtener ciertas garantías.
Podemos encontrar escenarios que utilizan Flume, Fluentd o Kafka, pero queremos centrarnos ahora en la integración de Scribe + Kestrel + Storm como una opción a considerar sobre todo en lo que se refiere al procesamiento de logs en tiempo real.
Lo iremos abordando en sucesivos posts, empezando a describir en éste a Scribe que nos serviŕa para recolectar los logs, los cuales serán publicados en colas Kestrel, de donde se alimentarían los KestrelSpout de Storm que es donde realmente se procesarán los logs. Llegado ese momento intentaremos usar Trident como capa de abstracción en lugar de los originales Bolts.
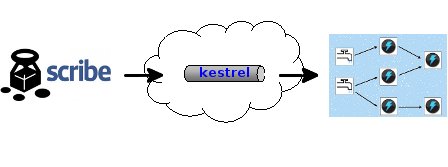 Toda una arquitectura con el fin de garantizar escalabilidad y robustez tanto en la recolección como en el procesamiento.
Toda una arquitectura con el fin de garantizar escalabilidad y robustez tanto en la recolección como en el procesamiento.
Entrando en materia, Scribe es un proyecto con origen en Facebook donde lo tienen instalado en miles de máquinas y procesando miles de millones de mensajes al día. Podemos describirlo como un servidor para ir agrupando logs en tiempo real.
Está diseñado para escalar a gran número de nodos y ser robusto a fallos de red o nodos. Se instala en cada nodo del sistema configurándolo para agrupar mensajes y enviarlos a un servidor central (o un grupo de servidores). Si el servidor central no está disponible se persiste el mensaje en local para su posterior envío. Los servidores centrales pueden pasar los mensajes a un destino final o incluso a otra capa superior de servidores. Nuestro destino final serían colas Kestrel.
Los clientes crearán entradas en un par (categoría, mensaje) . La categoría es una descripción de alto nivel que indica el destino del mensaje, que será configurado en el servidor. Ésto permite mover los almacenes de datos cambiando la configuración en los servidores en lugar de en los clientes.
Scribe proporciona el siguiente IDL para la comunicación. Al ser Thrift, permitirá implementaciones en distintos lenguajes.
enum ResultCode
{
OK,
TRY_LATER
}
struct LogEntry
{
1: string category,
2: string message
}
service scribe extends fb303.FacebookService
{
ResultCode Log(1: list messages);
}
Scribe consigue mayor flexibilidad con el concepto «Store». Un Store se carga dinámicamente desde archivos de configuración sin necesidad de parar los servidores. Se implementan como una jerarquía de clases, por lo que pueden contener otros Stores. De esta manera se puede combinar y ordenar distintas funciones cambiando la configuración.
Existen varios tipos:
- file, para escribir a disco local o nfs
- buffer, contempla un Store secundario si el primario no está disponible
- network, hacia otro scribe server
- bucket, conjuntos de Stores deciendo a donde enviar en función de un código
- thriftfile, escribe a un fichero Thrift TFileTransport
- null, para descartar mensajes
- multi, reenvía a múltiples Stores
Un ejemplo de configuración de tipo buffer defininiendo su primario y secundario quedaría así:
<store>
category=default
type=buffer
buffer_send_rate=1
retry_interval=30
retry_interval_range=10
<primary>
type=network
remote_host=wopr
remote_port=1456
</primary>
<secondary>
type=file
file_path=/tmp
base_filename=thisisoverwritten
max_size=10000000
</secondary>
</store>A pesar de un diseño robusto, Scribe no proporciona garantía transaccional. En palabras traducidas de los creadores: «es lo suficientemente fiable para recolectar toda la información durante casi todo el tiempo, pero no totalmente fiable, ya que requeriría protocolos pesados y uso excesivo de disco».
Debemos quedarnos con que obtenemos un gran rendimiento en detrimiento de la fiabilidad en los siguientes casos:
- Si un cliente no puede conectar al nodo local o central se perderá el mensaje.
- Si un servidor «explota» podría perder una pequeña cantidad de información en memoria que aún no haya sido persistida.
- Se perderían datos en caso de fallo múltiple de componentes, como por ejemplo que no sea posible conectar a ningún servidor central y el disco duro esté lleno.
- Algunas raras condiciones de timeout podría provocar la duplicidad de mensajes.
Aumentando el número de servidores centrales y configurando varias capas de servidores tenderiamos a anular las probabilidades de fallo.
Si habéis llegado hasta aquí siento deciros que lo divertido vendrá en la siguiente entrega: instalarlo, configurarlo y probarlo

Deja un comentario