
Ayer publicaba este post en el que me refería a los pasos a realizar para hacer funcionar Hadoop en Windows.
Pues bien! Ya lo tengo funcionando 😀 (que gustito le va a dar a mi portátil no tener que arrancar una máquina virtual para desarrollar sobre Hadoop!!!
Ahí un ls sobre HDFS:

Eso sí, el artículo en el que me basé
http://v-lad.org/Tutorials/Hadoop/00%20-%20Intro.html
se refería a una versión muy antigua de Hadoop, la 0.20, cuando la estable es la 1.1.1.
Para hacer funcionar Hadoop 1.1.1 hay que hacer unos pequeños cambios:
1 ) En el comando ssh-host-config si usáis Windows 7 o superiore debéis seleccionar
*** Query: Should privilege separation be used? (yes/no) yes
Y no como dice en la guía
2) Los ficheros a editar en la versión 1.1.1 de Hadoop son otros:
2.1) En %HADOOP%/conf/core-site.xml
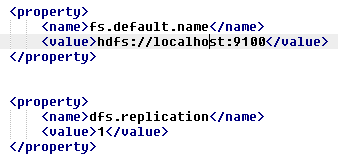
2.2) En %HADOOP%/conf/mapred-site.xml
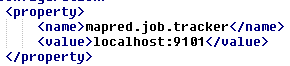
3) Si al arrancar el tasktraker os da este error:

Hay que aplicar esta solución: https://issues.apache.org/jira/browse/HADOOP-7682
Que básicamente consiste en:
Copiar https://github.com/downloads/congainc/patch-hadoop_7682-1.0.x-win/patch-hadoop_7682-1.0.x-win.jar a %HADOOP%/lib
Edito core-site.xml añadiendo:

En hadoop-1.1.1 tampoco viene el JAR del plugin de Eclipse. Los pasos para compilarlo son sencillos, pero eso para otro post!!!

Deja un comentario