
Lo más normal es que en las organizaciones que se plantean o ya usan aproximaciones Big Data (en nuestro caso Hadoop) exista una infraestructura completa: Servidores de ficheros, de backups, bases de datos,…
Por eso es importante cuando una organización se plantea el uso de aproximaciones Big Data ver cómo encajan con la infraestructura existente.
En el escenario de las bases de datos (RDBMS como Oracle, SQL Server, DB2,…) una aproximación usual es seguir usando estas bases de datos para consultas online y extraer los datos a Hadoop para permitir hacer datawarehouse y extraer incluso recomendaciones.
En la figura puede verse este escenario:
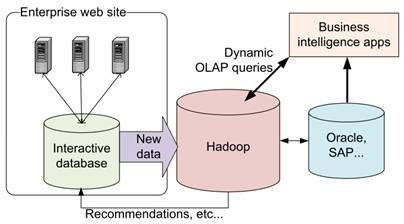
Así aprovechamos las virtudes de las bases de datos para gestionar transaccionalidad, miles de queries por segundo que devuelven resultados en tiempo real,… y las de Hadoop como la de no necesitas vistas prematerializadas para hacer datawarehouse o ser capaz de procesar petabytes.

En este escenario es especialmente útil Sqoop (del que ya hablamos en este post).
Sqoop permite:
· Importar (y exportar) datos de nuestro base de datos relacional a HDFS.
· Permite importar un subconjunto de tablas, aplicar sentencias WHERE,…
· Importa los datos a través de trabajos MapReduce para no saturar la base de datos
· Puede importar desde cualquier base de datos JDBC (aunque algunos fabricantes como Oracle o Microstrategy han hecho conectores nativos para Sqoop)
· Es capaz de importar a HDFS como ficheros de texto o SequenceFiles
· Puede realizar imports incrementales (sólo extrayendo filas desde último import)
Su sintaxis es:
>sqoop import [opciones]
>sqoop import-all-tables [opciones]
>sqoop list-tables [opciones]
>sqoop export [opciones]
>sqoop help
Donde [opciones] puede ser:
–connect
–username
–password
–table
–where
Un ejemplo completo de su uso podría ser:
>sqoop import –username scott –password tiger –connect jdbc:mysql://<host>:<port>/mibasedatos –table empleados –where "id > 1000"

Deja un comentario